目次
単回帰分析とは?
単回帰分析の目的
単回帰分析は、1つの独立変数(説明変数)を用いて、1つの従属変数(目的変数)を予測する手法です。この方法は、データ間の関係性を明確にすることで、将来の値やトレンドを推定する際に役立ちます。
単回帰分析を学ぶ理由
- データの相関関係を理解する
- 簡易的な予測モデルを構築する
- ビジネスデータの傾向を把握し、意思決定を支援する
学習すること
単回帰分析を効果的に学ぶためには、以下の内容を理解する必要があります。
基本的な数学的モデル
単回帰分析は以下の数式で表されます:
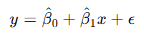
- y:従属変数(目的変数) ※出力変数とも呼ぶようです
- x:独立変数(説明変数) ※入力変数とも呼ぶようです
- β^0: 切片(y軸の交点)
- β^1: 傾き(変数間の関係性を示す)
- ϵ :誤差(観測値と予測値の差)
用語の理解
モデル
単回帰分析では、線形関係を仮定したモデルが利用されます。このモデルは、データが直線的に分布している場合に有効です。
ハット記号 (^)
ハット記号は、推定値や予測値を表すために使用されます。たとえば、y^ は観測値 y に対する予測値を意味します。
パラメータ
モデルのパラメータは以下の2つで構成されます。
- 切片 (β^0): 回帰直線がy軸と交わる点。
- 傾き (β^1): 独立変数が1単位増加したときの従属変数の変化量。
評価関数(SSE)
モデルの性能を評価するための指標として以下を学ぶ必要があります:
1.決定係数 (R^2)
- 予測モデルがデータをどの程度説明できているかを示す。
- R^2 = 1 に近いほど、モデルの精度が高い。
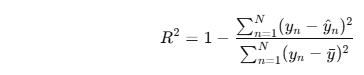
2.平均二乗誤差 (MSE)
- 予測値と実測値の誤差を平方平均したもの。
- Q.何故二乗するのか A.整数値で誤差比較するため
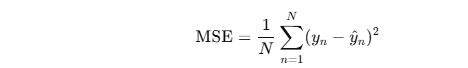
3.最小二乗法
- 最小二乗法(Least Squares Method)は、回帰分析でモデルのパラメータ(切片 と傾き )を求めるための基本的な手法
- 予測値と実測値の差の二乗の総和(SSE)を最小化することで、データに最も適合する直線(回帰直線)が求められる
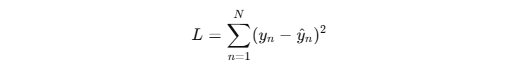



以下のPythonコードで、最小二乗法の計算手順を確認してみる。
import numpy as np
# サンプルデータ
x = np.array([1, 2, 3, 4, 5]) # 独立変数
y = np.array([2, 4, 5, 4, 5]) # 従属変数
# 平均値の計算
x_mean = np.mean(x)
y_mean = np.mean(y)
# 傾き (β1) の計算
numerator = np.sum((x - x_mean) * (y - y_mean)) # 分子
denominator = np.sum((x - x_mean) ** 2) # 分母
beta_1 = numerator / denominator
# 切片 (β0) の計算
beta_0 = y_mean - beta_1 * x_mean
# パラメータの出力
print(f"切片 (β0): {beta_0}")
print(f"傾き (β1): {beta_1}")
# 予測値の計算
y_pred = beta_0 + beta_1 * x
print(f"予測値: {y_pred}")
学習内容の手順
1. 理論の理解
- 単回帰モデルの構造
- パラメータ推定の方法(最小二乗法)
2. データの準備
- データの確認(欠損値や外れ値の確認)
- 独立変数と従属変数の選定
3. 実装方法
Pythonを用いたサンプルコード
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# データの準備
data = {
"StudyHours": [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], # 独立変数
"TestScore": [2, 4, 5, 8, 10, 11, 14, 16, 18, 20], # 従属変数
}
df = pd.DataFrame(data)
# データの確認
print("データの確認:")
print(df)
# 欠損値の確認
print("\n欠損値の確認:")
print(df.isnull().sum())
# データの可視化
plt.scatter(df["StudyHours"], df["TestScore"], color="blue")
plt.title("Study Hours vs Test Score")
plt.xlabel("Study Hours")
plt.ylabel("Test Score")
plt.show()
# データを独立変数 (X) と従属変数 (y) に分割
x = df["StudyHours"].values.reshape(-1, 1)
y = df["TestScore"].values
# モデルの構築と学習
model = LinearRegression()
model.fit(x, y)
# モデルのパラメータ
print("\nモデルのパラメータ:")
print(f"切片 (β0): {model.intercept_}")
print(f"傾き (β1): {model.coef_[0]}")
# 予測値の計算
y_pred = model.predict(x)
# 暗黙的な評価関数の処理
mse = mean_squared_error(y, y_pred) # MSEの計算(平均二乗誤差)
r2 = r2_score(y, y_pred) # R^2(決定係数)
print("\n暗黙的な評価関数の結果:")
print(f"平均二乗誤差 (MSE): {mse}")
print(f"決定係数 (R^2): {r2}")
# 明示的な評価関数の処理
# 1. 二乗誤差の総和 (SSE)
sse = np.sum((y - y_pred) ** 2)
# 2. MSE の計算
mse_manual = sse / len(y)
# 3. 決定係数 (R^2) の計算
total_variance = np.sum((y - np.mean(y)) ** 2) # 全分散
r2_manual = 1 - (sse / total_variance)
print("\n明示的な評価関数の結果:")
print(f"二乗誤差の総和 (SSE): {sse}")
print(f"平均二乗誤差 (MSE, 手動計算): {mse_manual}")
print(f"決定係数 (R^2, 手動計算): {r2_manual}")
# 結果のプロット
plt.scatter(df["StudyHours"], df["TestScore"], color="blue", label="観測値")
plt.plot(df["StudyHours"], y_pred, color="red", label="回帰直線")
plt.title("Linear Regression Model")
plt.xlabel("Study Hours")
plt.ylabel("Test Score")
plt.legend()
plt.show()
# インプット値と予測値の出力
print("\nインプット値と予測結果:")
test_hours = np.array([[3], [7], [10]])
predicted_scores = model.predict(test_hours)
for hours, score in zip(test_hours.flatten(), predicted_scores):
print(f"勉強時間: {hours} 時間 -> 予測テストスコア: {score:.2f}")
※評価関数を最小化する作業は、回帰モデルの学習過程で自動的に行われています。具体的には、LinearRegression モデルを構築する際、最小二乗法(Least Squares Method) が内部的に使用され、評価関数(通常は二乗誤差)が最小化されています。

結果の出力
- 暗黙的な評価関数の結果
- 明示的な評価関数の結果
- 回帰直線をプロットして視覚的に確認