目次
サンプルプログラム実装と検証(線形回帰)(1)
プログラムの流れ
- 利用するライブラリのインポート
- データセットの用意
- データ読み込み
- データの可視化(ペアプロット・ヒストグラム・相関係数)
- 本来ならば、可視化→確認→データ前処理 のプロセスがある。
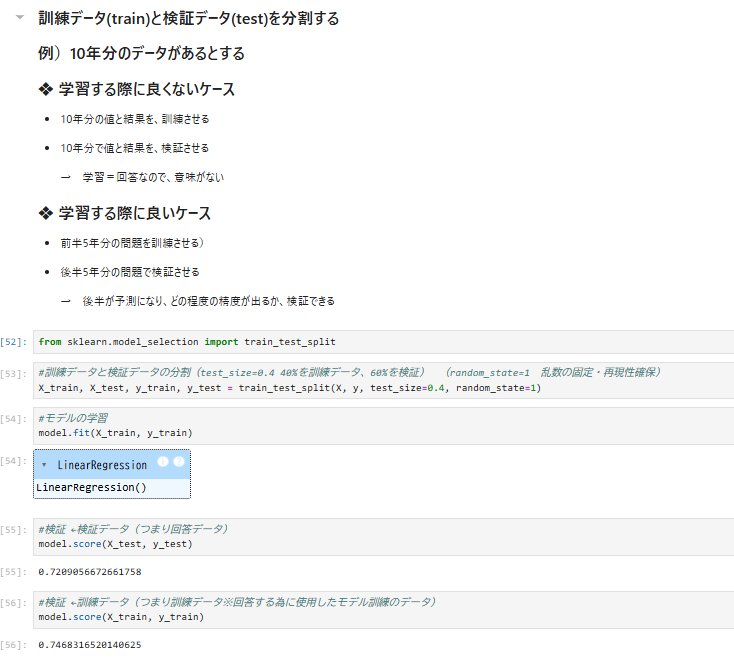
- 訓練データとテストデータに分割
- 線形回帰モデルの学習
- 訓練データ・テストデータの精度確認
- 改善のためのアプローチ提案
1. モデル用のデータの用意
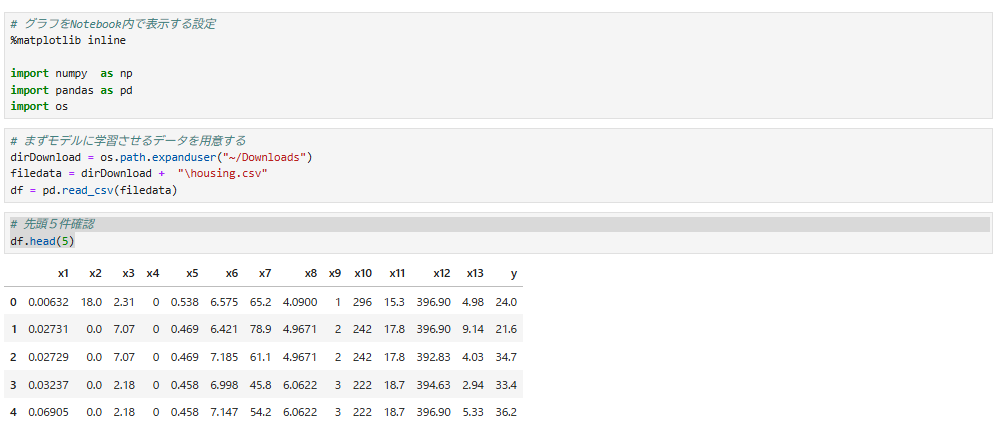
2. データ取得の確認
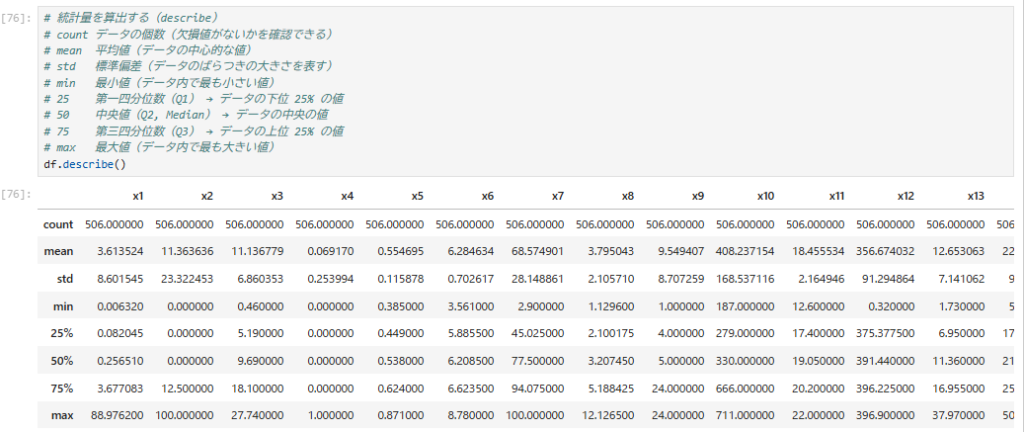
3. データ情報確認 統計量を算出
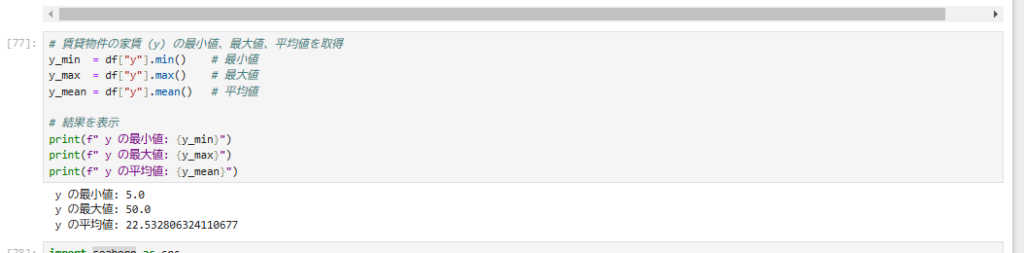
4.目的変数の最大値・最小値・平均値 確認
5.ペアプロットを可視化し、正規分布に近い変数を探す

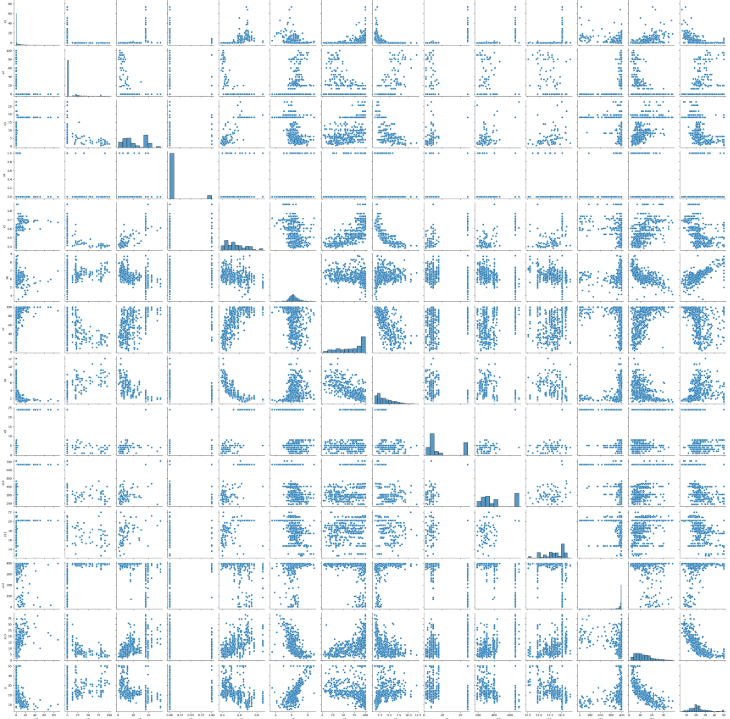
※ここではサンプルプログラムとしての実装の為、大枠の流れのみ実装・確認する。
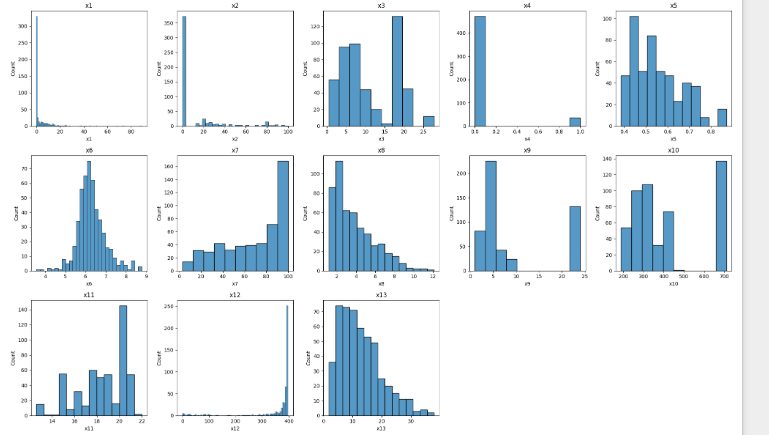
6.ヒストグラムを確認する
※ヒストグラムの目的は「正規分布の形状を確認すること」だけではなく
外れ値・偏り・データのスケールなど、データの性質全体を理解することにある。
詳細な解説については別途記載、リンク先の内容を参照。
全変数の分布をざっくり確認
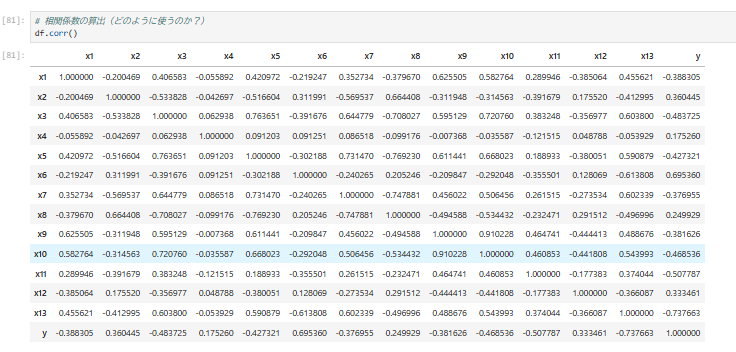
7.相関関係の可視化
※相関関係の分析には、特徴量の選択、多重共線性の確認、外れ値の影響、データの正規化など
色々な観点があるため、詳細な解説については別途記載、リンク先の内容を参照。
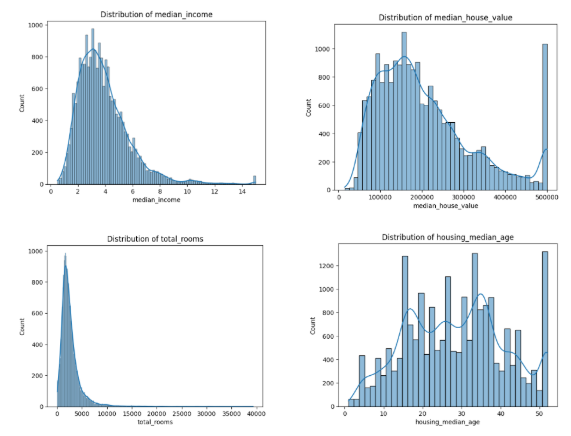
8.分布のプロット
ここでも、正規分布を確認するが、median_income, median_house_value, total_rooms, housing_median_age など、重要な変数を詳細に可視化している部分が異なる。また、KDE(カーネル密度推定)を追加して、データのなめらかな分布を視覚的に強調している。住宅価格(median_house_value)の上限50万ドルにデータが集中している点が明確に分かる。
重要な変数にフォーカスして詳細に分析

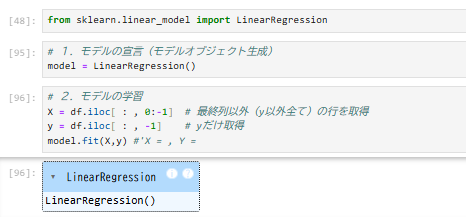
9.説明変数、目的変数を指定して、モデルに学習と訓練をさせる
結果
とりあえず、詳細まではまだ把握できてはいないが、重回帰分析を行うためのプロセスについての概要を把握した。ここからデータの精度を上げる為に、様々な知識が必要になってくるのと考えられる。一旦流れをつかむための学習であるため、深堀せずに次に進む。