◆ ステップ2:WAVファイルを使ってSTTを試す ◆
このステップでは、Azure Speech-to-Text(STT)API を使って、既存のWAVファイルをテキストに変換 します! 🎤 → 📝
目次
① 事前準備
✅ 1. 必要なライブラリをインストール
まず、仮想環境をアクティブ化し、必要なライブラリをインストールします。
pip install azure-cognitiveservices-speech
✅ インストール完了後、次へ進みます
✅ 2. 音声データ(WAVファイル)の準備
- 方法1:既存のWAVファイルを使用
- すでに
sample_audio.wavというWAVファイルがある場合、そのまま利用
- すでに
- 方法2:新しく音声を録音
- Windows: 「ボイスレコーダー」アプリを使用
- macOS: 「QuickTime Player」 → 「新規オーディオ録音」
- スマホ: 標準の録音アプリで「Hello, this is a test.」と言って録音
- ファイル形式をWAVに変換
- Audacity や FFmpeg を使って
sample_audio.wavに変換
- Audacity や FFmpeg を使って
✅ 音声データの準備ができたら、次へ進みます!
② PythonでSTTを実装
PyCharmで新しいPythonスクリプトを作成し、以下のコードを実行してください。
(stt_from_wav.py という名前でファイルを作成)
📝 stt_from_wav.py
import azure.cognitiveservices.speech as speechsdk
import winreg # Windowsのレジストリを操作するためのモジュール
from convertwav import ConvertWAV
# 🔹 設定するファイルパス
AUDIO_FILE = "sample_jp.wav"
# AUDIO_FILE_CONVERT = "sample_jp_convert.wav"
# AUDIO_FILE_CLEAN = "sample_jp_clean.wav"
# 🔹 レジストリからAPIキーとリージョンを取得する関数(HKEY_LOCAL_MACHINEに対応)
def get_registry_value(key_path, value_name, hive=winreg.HKEY_LOCAL_MACHINE):
try:
with winreg.OpenKey(hive, key_path, 0, winreg.KEY_READ) as key:
value, _ = winreg.QueryValueEx(key, value_name)
return value
except FileNotFoundError:
print(f"⚠️ レジストリキーが見つかりません: {key_path}\\{value_name}")
return None
def get_language_from_filename(audio_file):
""" ファイル名に `_jp` または `_en` が含まれているかで言語を判断 """
if "_jp" in audio_file:
return "ja-JP" # 日本語で認識
elif "_en" in audio_file:
return "en-US" # 英語で認識
else:
return "ja-JP" # デフォルトは日本語認識
def recognize_speech_from_file(audio_file, speech_key, service_region):
""" WAVファイルをSTTにかけて文字起こしを行う """
recognition_language = get_language_from_filename(audio_file)
print(f"🛠 設定された言語: {recognition_language}")
# # 音声情報の確認と変換
# converter = ConvertWAV(AUDIO_FILE)
# converter.check_audio_properties()
# converter.convert_audio_format(AUDIO_FILE_CONVERT)
#
# # 変換後の音声情報を確認
# converter = ConvertWAV(AUDIO_FILE_CONVERT)
# converter.check_audio_properties()
# converter.plot_waveform()
# converter.remove_silence(AUDIO_FILE_CONVERT, AUDIO_FILE_CLEAN)
# 無音時間を最大20秒まで許容
speech_config = speechsdk.SpeechConfig(subscription=speech_key, region=service_region)
speech_config.set_property(
property_id=speechsdk.PropertyId.SpeechServiceConnection_InitialSilenceTimeoutMs,
value="10000"
)
# 言語設定
speech_config.speech_recognition_language = recognition_language
audio_config = speechsdk.audio.AudioConfig(filename=AUDIO_FILE)
# 音声認識の実行
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config, audio_config=audio_config)
print("🎤 音声認識中...")
result = speech_recognizer.recognize_once()
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
print("✅ 認識結果:", result.text)
return result.text
elif result.reason == speechsdk.ResultReason.NoMatch:
print("❌ 認識できませんでした")
elif result.reason == speechsdk.ResultReason.Canceled:
print("❌ キャンセルされました:", result.cancellation_details.reason)
def main():
""" メインメソッド """
# 🔹 レジストリの保存パス(HKEY_LOCAL_MACHINE\SOFTWARE\SpeechService)
REGISTRY_PATH = r"SOFTWARE\SpeechService"
# 🔹 APIキーとリージョンをレジストリから取得
speech_key = get_registry_value(REGISTRY_PATH, "SPEECH_SERVICE_KEY1", hive=winreg.HKEY_LOCAL_MACHINE)
service_region = get_registry_value(REGISTRY_PATH, "SPEECH_SERVICE_REGION", hive=winreg.HKEY_LOCAL_MACHINE)
# 🔹 取得したキーを確認(デバッグ用)
if not speech_key:
raise RuntimeError("❌ APIキーの取得に失敗しました。レジストリを確認してください。")
if not service_region:
raise RuntimeError("❌ リージョンの取得に失敗しました。レジストリを確認してください。")
print(f"✅ APIキー取得成功: {speech_key[:5]}...(セキュリティのため一部のみ表示)")
print(f"✅ リージョン取得成功: {service_region}")
# 音声認識を実行
recognized_text = recognize_speech_from_file(AUDIO_FILE, speech_key, service_region)
print(f"🎯 最終認識結果: {recognized_text}")
# 🔹 スクリプトのエントリーポイント
if __name__ == "__main__":
main()
✅ コードを保存し、次へ進みます
③ 実行と結果確認
- スクリプトを実行
python stt_from_wav.py
- 期待される出力
- 成功すると
✅ 認識結果: <変換されたテキスト>が表示される - エラーが出た場合、メッセージを確認
- 成功すると
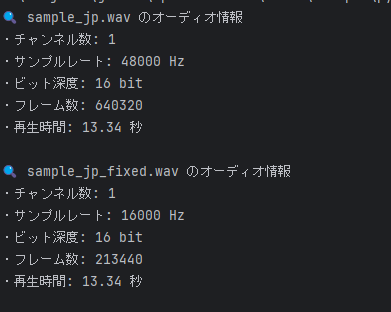
問題が出たので確認した箇所 ①
サンプルレートが16000Hz でないとうまく認識しないらしい。
Azureの推奨のようです。変換して再度確認したところまた上手くいかなかった。

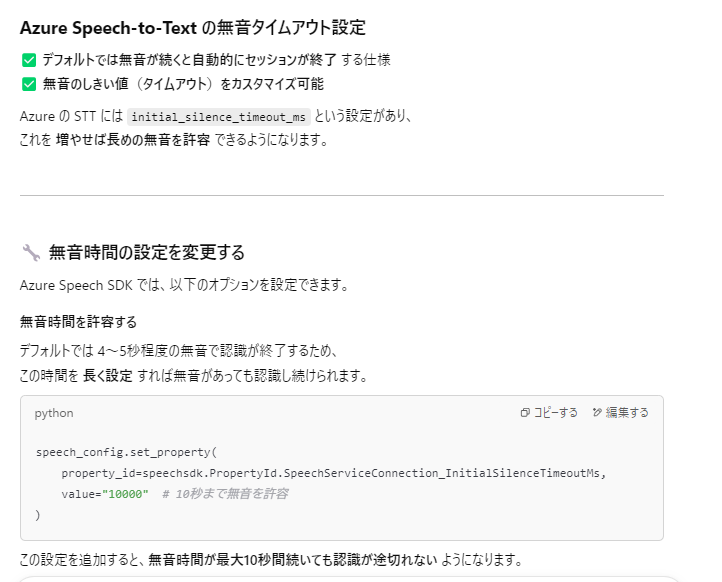
問題が出たので修正した箇所 ②
無音時間が長かった場合、無音時間で終了してしまうこともあるとの事。(繊細過ぎて使えないので恐らく設定がありそうだけど、今回は音声を文字に起こして翻訳して音声に先ずはしてみようってコンセプトなので無視する。調査だけ行った。以下図より。
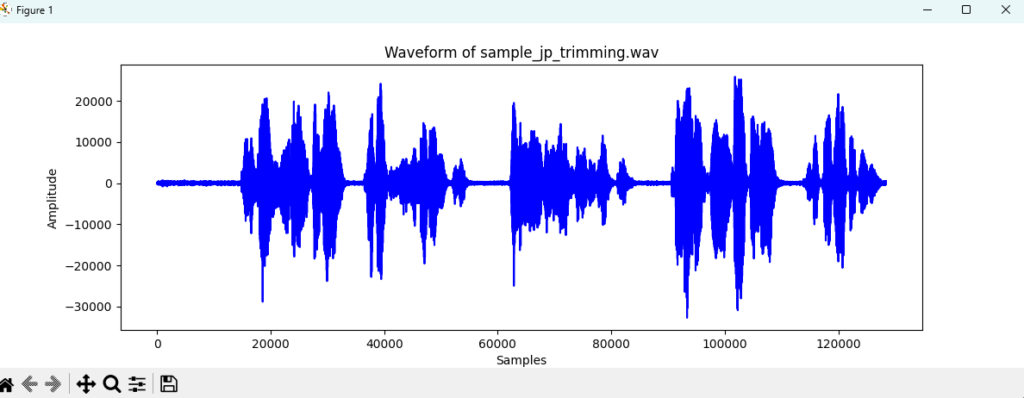
無音時間や、起動時の雑音などが入ってたので、削除する。(上:削除前、下:削除後)
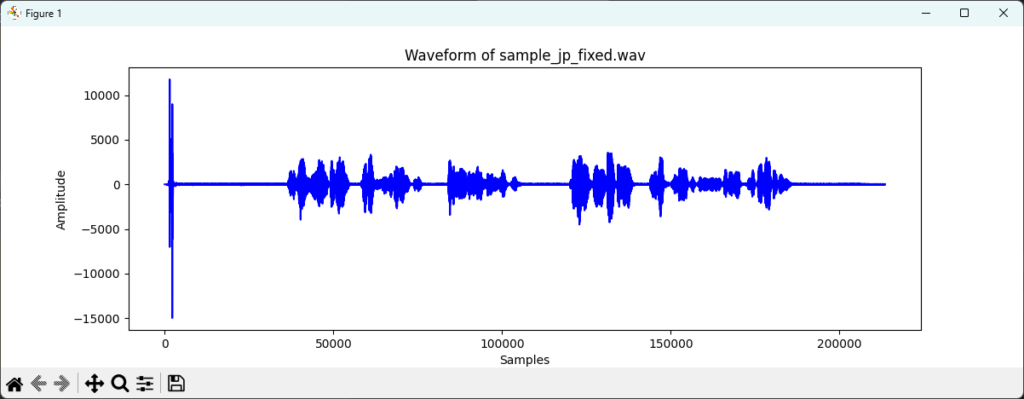
sample_jp.wav を使用した場合

sample_jp_trimming.wav を使用した場合

すると正常に音声データから文字おこしがおこなえた。
✅ スクリプトを実行して音声認識できればステップ2完了。次のステップを試す。
>>>> ステップ3:WAVファイルを使ってSTTからTTSを試す①