◆◆ ステップ3:リアルタイムSTTを試す③ ◆◆
目次
次のステップ: STT → 翻訳 → TTS の統合
ここまでで STT(音声認識)・翻訳(Translator API)・TTS(音声合成) の個別処理の実装し動作確認できました。次は この3つのプロセスを統合 し、「音声(日本語) → 音声(英語)」を自動化するスクリプト を作成します。
📌 統合スクリプトの設計
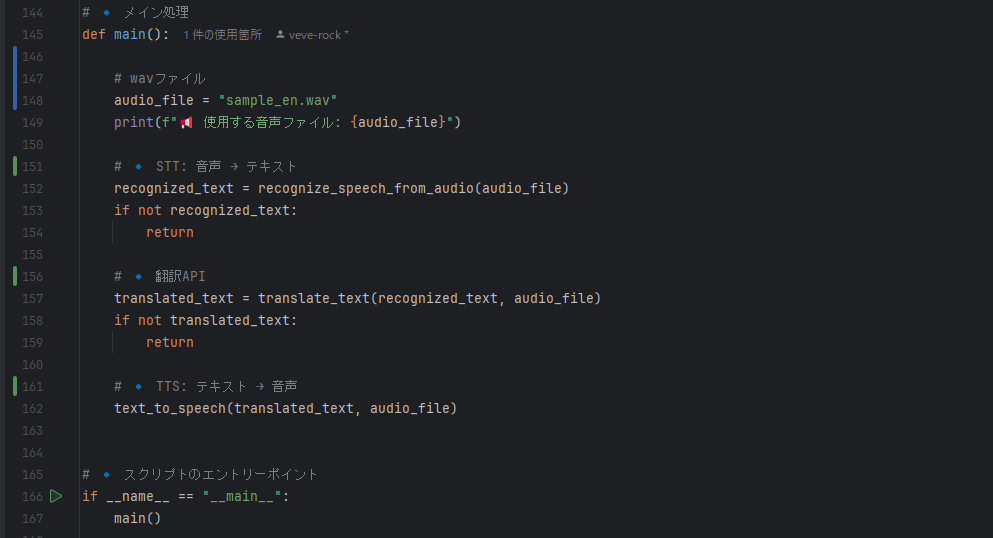
1️⃣ 音声認識(STT)
- 日本語の音声ファイル を Azure Speech-to-Text に渡す
- テキスト(日本語)に変換
2️⃣ 翻訳(Translator API)
- 日本語のテキストを 英語に翻訳
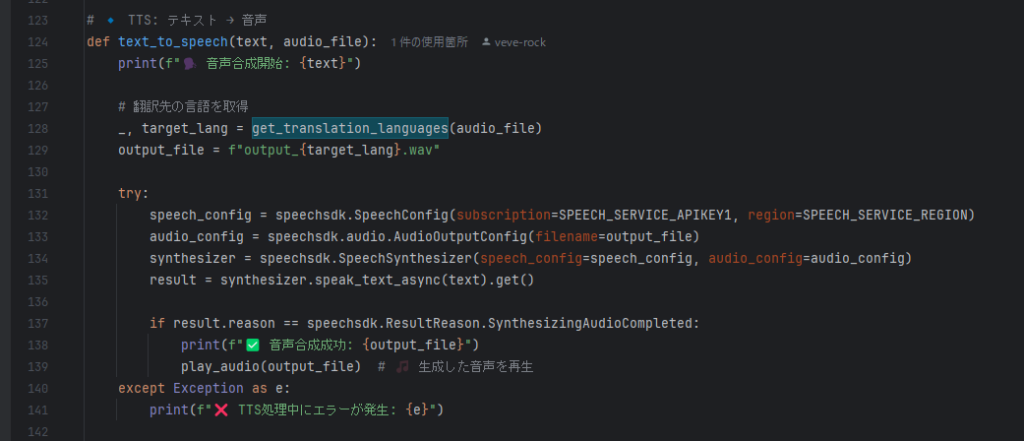
3️⃣ 音声合成(TTS)
- 翻訳された英語のテキストを TTS で音声化
output.wavに保存 & 再生
✅ 実装
- speech_translation.py
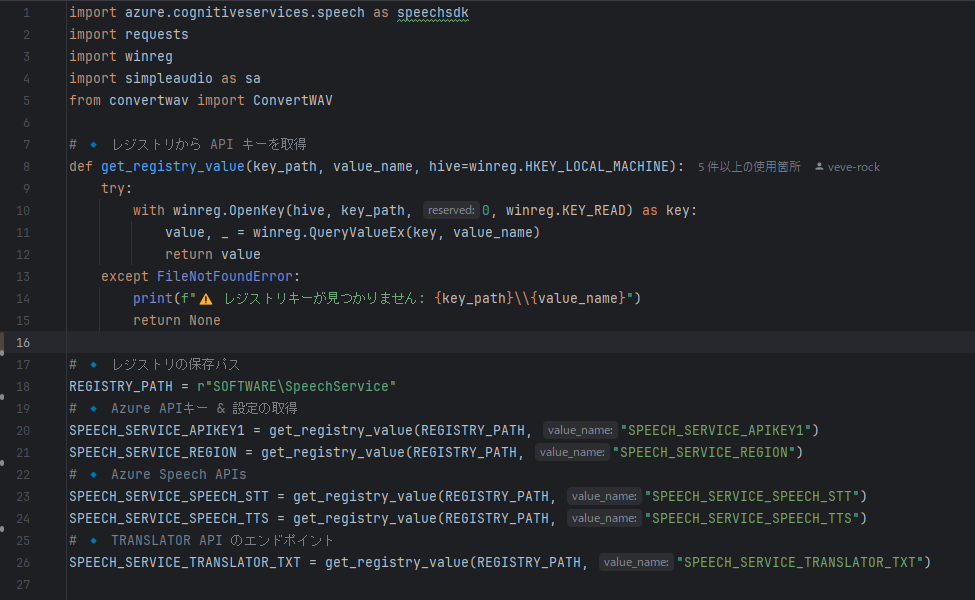
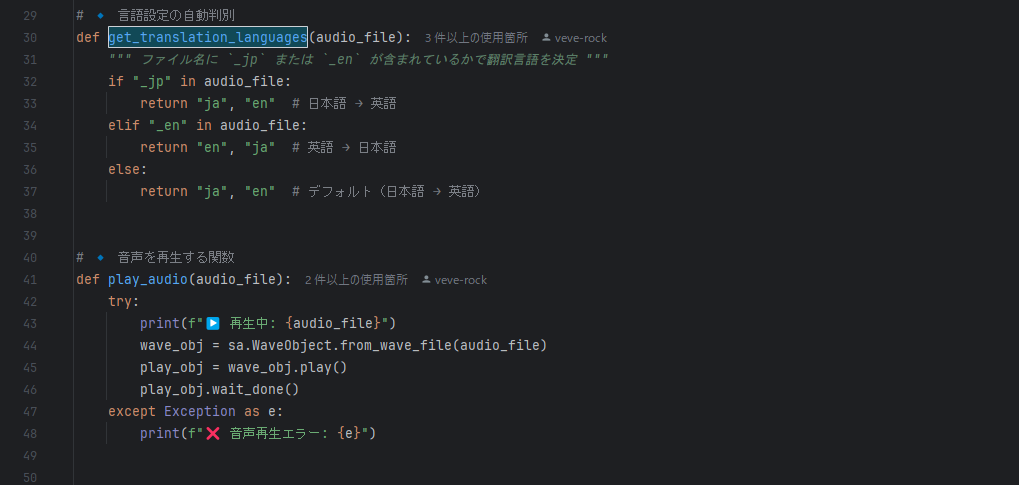
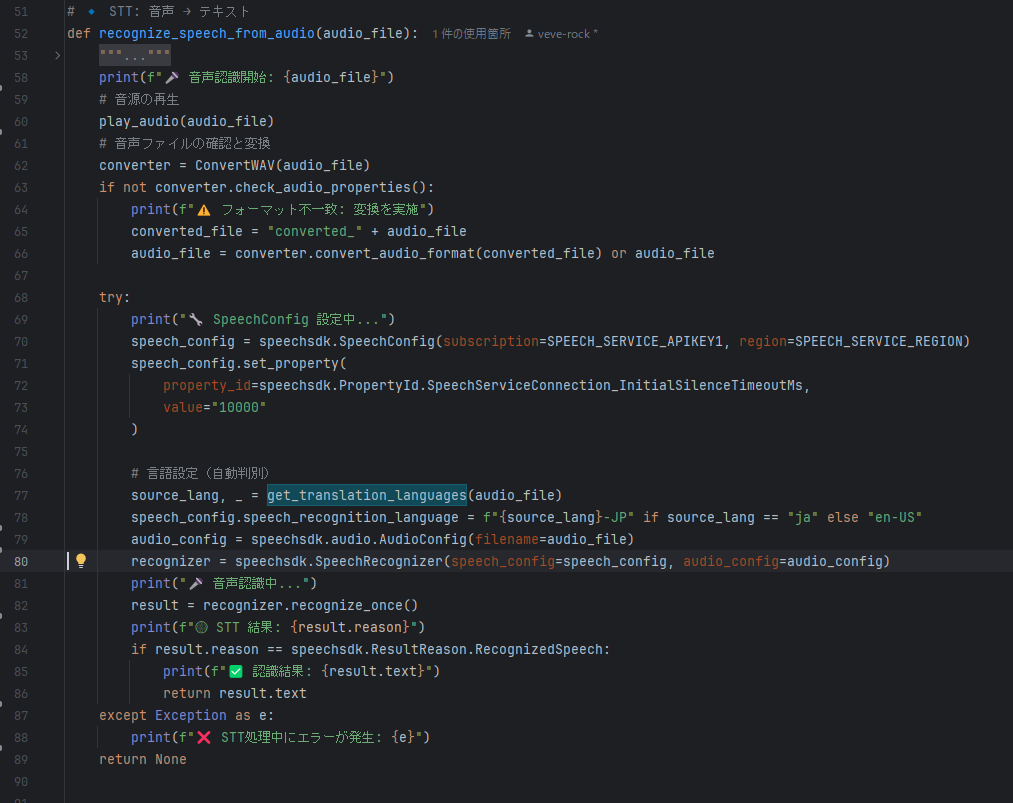
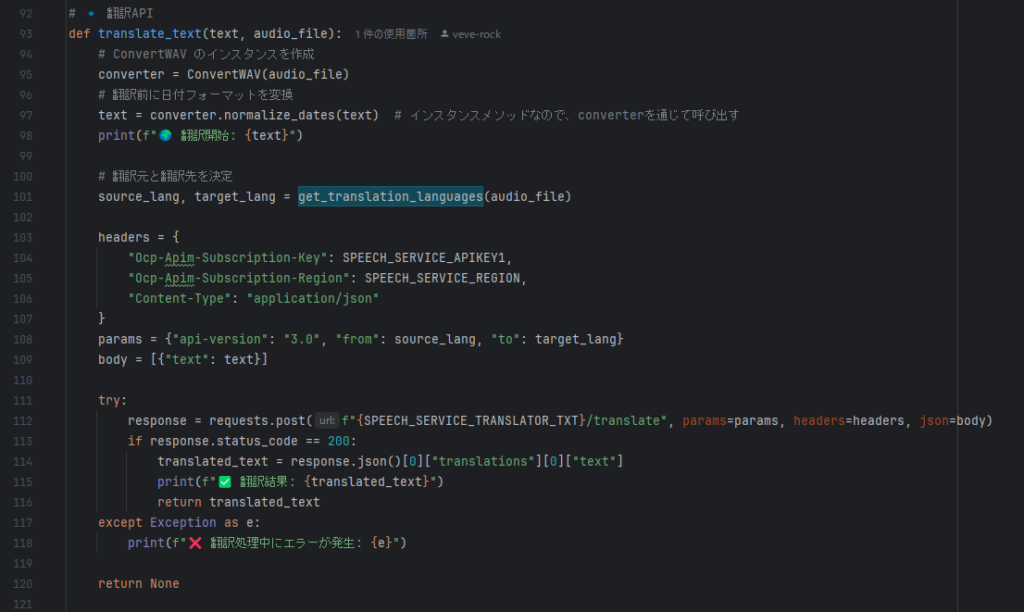
- convert_wav.py
3️⃣ output.wav を再生し、英語音声が正しく出力されるか確認 → 完了
🎯 まとめ
✅ STT(音声認識) → 翻訳 → TTS(音声合成)を統合
✅ 日本語の音声ファイルを自動で英語音声に変換するシステムが完成
✅ エラーハンドリング付きで、問題があれば詳細を表示
📌懸念点
英語を文字化した際に、日付部分で問題が出た部分的な問題を手で修正、ではなく、学習させる事がAIを使うという事だと考える為、あえて修正は実装で対応せずに次に進む。具体的には英語の際、年月日時分秒の時分秒を数字の羅列でしか言わないようで、文字化したときに141723などとなり、日本語で十四万千七百二十三と読んだ。
次のステップ
1️⃣ このコードを実行して、日本語の音声が正しく英語音声に変換されるか確認
2️⃣ 生成された output.wav の品質を確認し、必要なら調整
3️⃣ 問題がなければ、リアルタイム処理(ストリーミング)に進む