目次
1.環境構築/動作確認
まずは環境構築から進めます。
🛠 Step 1: Docker環境の構築
1-1. Dockerのインストール確認
Dockerが正しくインストールされているか確認しましょう。
docker --version
docker-compose --version
✅ 正しくインストールされている場合
以下のようなバージョン情報が表示されればOKです。
Docker version 24.0.7, build afdd53b
Docker Compose version v2.23.3-desktop.2
🚨 インストールされていない場合
- Docker公式サイト から Docker Desktop をインストール
- Dockerを起動し、
WSL 2またはHyper-Vを有効にする - PowerShellを開き、もう一度
docker --versionを確認 - 「Switch to Linux containers…」がある場合 → クリックしてLinuxコンテナに切り替える。
>>なぜLinux環境で環境構築するのか?
📂 Step 2: 作業ディレクトリの作成
PowerShellを開き、作業ディレクトリを作成します。
※作業フォルダ D:\Programs\github\speech_processing としました。
# 作業フォルダを D:\Programs\github\speech_processing に作成
New-Item -ItemType Directory -Path "D:\Programs\github\speech_processing"
Set-Location -Path "D:\Programs\github\speech_processing"
作成したフォルダの中に Dockerfile と docker-compose.yml を作成します。
# Dockerfile の作成
New-Item -ItemType File -Name "Dockerfile"
# docker-compose.yml の作成
New-Item -ItemType File -Name "docker-compose.yml"
🐍 Step 3: Dockerfile の作成
エディタ(VSCodeやNotepad)で Dockerfile を開き、以下の内容をコピーして保存してください。
# Python 3.9 イメージを使用
FROM python:3.9
# 作業ディレクトリの設定
WORKDIR /app
# 必要なパッケージをインストール
RUN apt-get update && apt-get install -y \
libsndfile1 \
&& rm -rf /var/lib/apt/lists/*
# Pythonライブラリのインストール
RUN pip install --upgrade pip && pip install \
numpy \
scipy \
matplotlib \
librosa \
torch torchvision torchaudio \
tensorflow \
jupyter \
seaborn \
pandas \
scikit-learn \
SpeechRecognition
# Jupyter Notebook を起動
CMD ["jupyter", "notebook", "--ip=0.0.0.0", "--port=8888", "--no-browser", "--allow-root"]
📜 Step 4: docker-compose.yml の作成
エディタ(VSCodeやNotepad)で docker-compose.yml を開き、以下の内容をコピーして保存してください。
version: "3.8"
services:
speech_analysis:
build: .
container_name: speech_processing
ports:
- "8888:8888"
volumes:
- .:/app
🚀 Step 5: Dockerコンテナのビルド & 起動
PowerShellで以下を実行し、コンテナをビルドします。
docker-compose up --build -d
起動後、コンテナのログを確認して Jupyter Notebook のURLを取得します。
docker logs speech_processing
表示されるURL例:
http://127.0.0.1:8888/?token=xxxxx
このURLをブラウザで開けば、Jupyter Notebook を使用できます。
📊 Step 6: 音声波形とスペクトログラム 動作確認
Jupyter Notebookを開いたら、新しいノートブックを作成し、以下のコードを試してください。
6-1. 音声波形の可視化
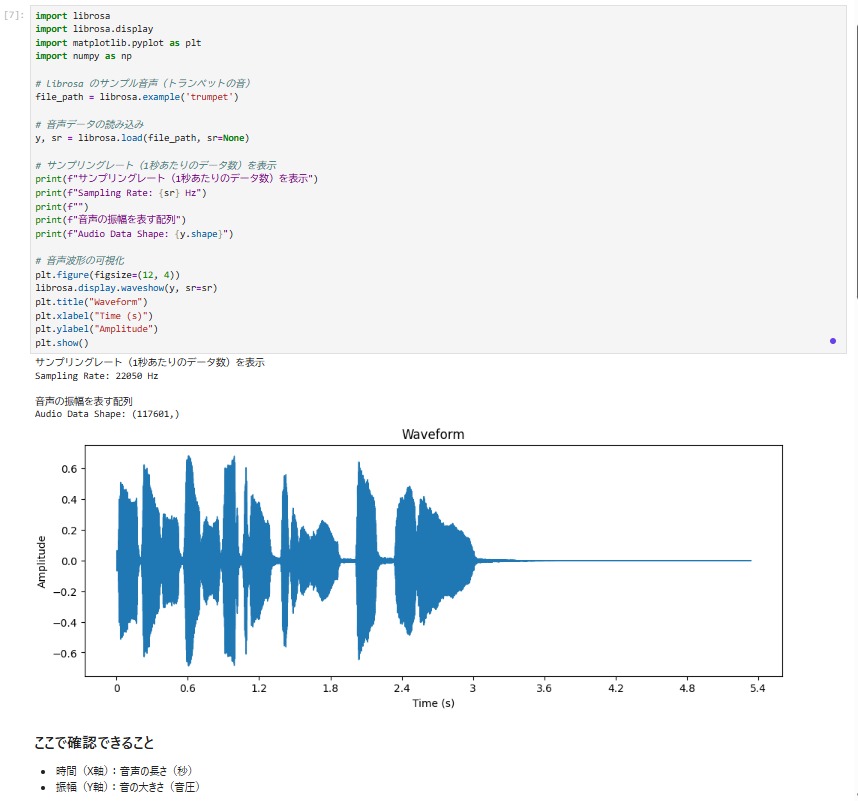
6-2. スペクトログラムの可視化
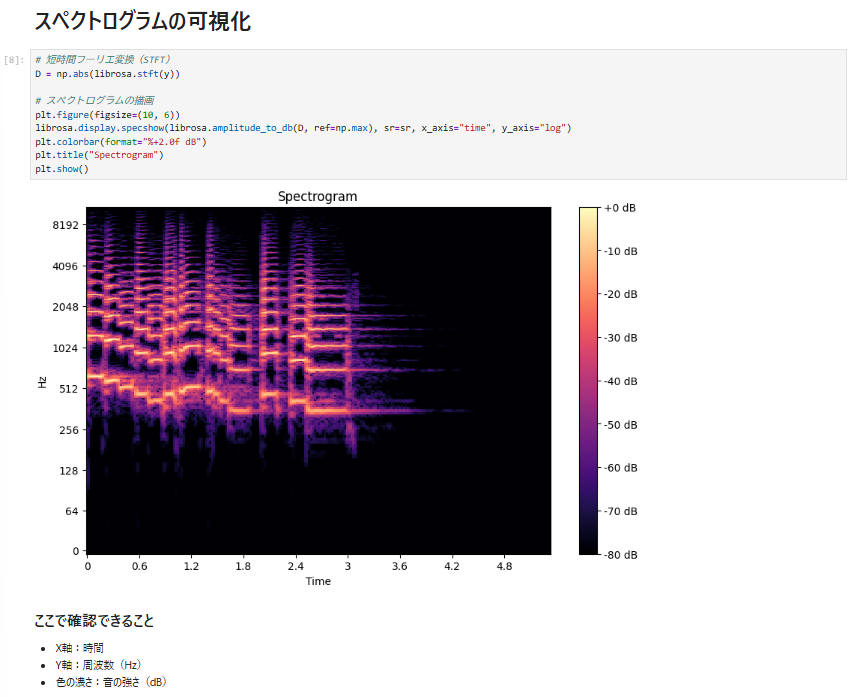
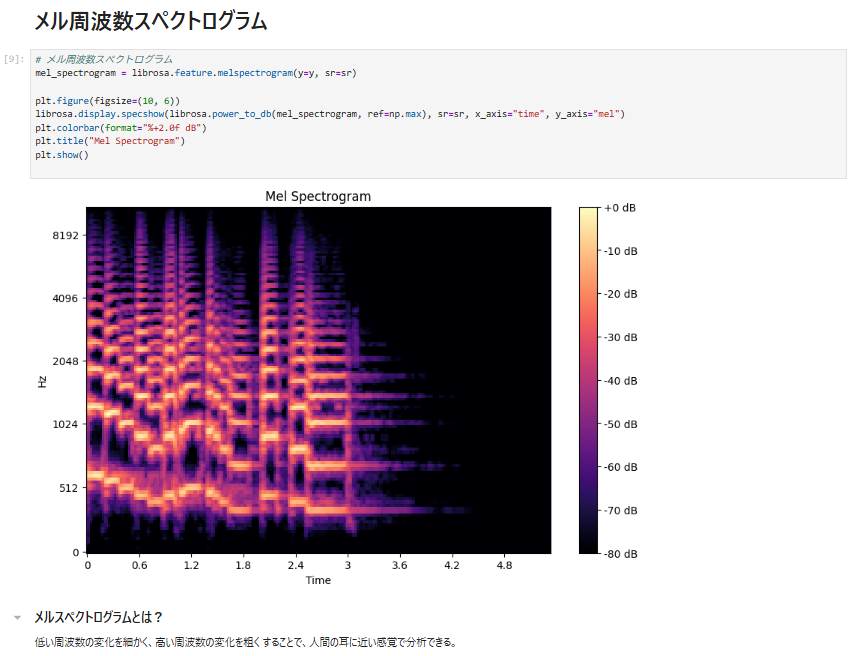
🎛 Step 7: 音声特徴量の抽出
音声特徴量を抽出してみましょう。
7-1. MFCC の取得
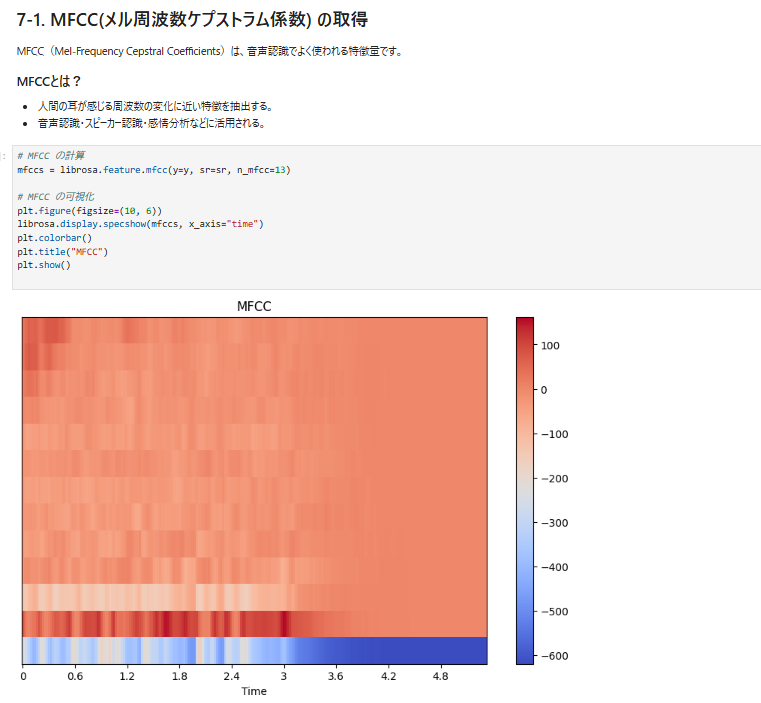
7-2. ゼロ交差率
7-3. スペクトルセントロイド
7-4. RMSエネルギー(音量の強さ)
7-5. スペクトルバンド幅
実装演習したこと
✅ Docker環境を構築し、Jupyter Notebookを動かす
✅ 音声波形とスペクトログラムを可視化する
✅ MFCCやゼロ交差率などの特徴量を抽出する