目次
音声データセットの選定
次は「音声データセットの選定と前処理」に進みます
Kaggleのデータセットを使い、音声データを準備します
Step 1: Kaggleのデータセットを選ぶ
✅ Step 1: Kaggle のデータセットを選ぶ
音声データセットには、以下の 2 つの選択肢 があります。
📌 ① Google Speech Commands Dataset
・英単語(yes, no, up, down など)を認識するデータセット
・短い単語(1秒以下の発話)の分類タスク向け
📌 ② Mozilla Common Voice
・長めの発話(文章単位)の音声データ
・言語ごとにデータがあり、音声認識(Speech-to-Text)向け
📌 今回は「Google Speech Commands Dataset」を選択
📍 音声分類タスクの準備として、このデータを使用して「音声を分類するモデル」を作る準備を進めます。
📍 Kaggle で音声データセットを検索
以下のコマンドを実行し、Kaggle にある "speech commands" のデータセットをリストアップします。
kaggle datasets list -s "speech commands"
✅ 出力されるリストから、データセットの名前を確認
📌 使用するデータセット
| Kaggle データセット名 | 特徴 | API 取得 |
|---|---|---|
| bahraleloom/tensorflow-speech-commands | API で取得可能 | ✅ |
| yashodhogra/speech-commands | yes/ no/ up/ down/ を含むがAPI取得不可 | ❌(手動) |
✅ 学習に必要なデータを網羅する yashodhogra/speech-commands をメインで使用
✅ API で取得可能な bahraleloom/tensorflow-speech-commands も補助として使う
Kaggle APIの取得・設定
Kaggle からデータセットをダウンロードするには、Kaggle APIの設定が必要です。
- Kaggleの公式サイト にアクセス
- 右上のプロフィールアイコンをクリック
- 「Account(アカウント)」を開く
- 「Create New API Token」 をクリック
kaggle.jsonというファイルがダウンロードされる

Windows での API キー設定
✅ kaggle.json を適切に配置し、アクセス権限を設定する。
# ✅ Kaggle API キー(kaggle.json)を保存するディレクトリを作成する
# 既にディレクトリが存在する場合は、そのまま維持(-Forceオプション)
New-Item -ItemType Directory -Path "$env:USERPROFILE\.kaggle" -Force
# ✅ Kaggle API キー(kaggle.json)をダウンロードフォルダから .kaggle フォルダに移動
# -Force オプションを指定して、上書き可能にする
Move-Item -Path "$env:USERPROFILE\Downloads\kaggle.json" -Destination "$env:USERPROFILE\.kaggle\" -Force
# ✅ kaggle.json のアクセス権限を変更(セキュリティ強化)
# - inheritance:r → 継承を無効化(他の権限を受け継がない)
# - grant *S-1-1-0:F → すべてのユーザー(Everyone)にフルコントロール権限を付与
# ※ Kaggle API を正しく動作させるために、適切な権限を設定
icacls "$env:USERPROFILE\.kaggle\kaggle.json" /inheritance:r /grant *S-1-1-0:F
Kaggle API のインストール
pip install kaggle
✅ Kaggle API をインストール。
Kaggle API の動作確認
$env:KAGGLE_CONFIG_DIR = "$env:USERPROFILE\.kaggle"
kaggle datasets list
✅ エラーが出ずにデータセット一覧が表示されればOK!
API でダウンロード可能なデータセットを確認
1️⃣ 「Speech Commands」系のデータセットを検索
kaggle datasets list -s "speech commands"
✅ 検索結果に 🔒(鍵マーク)が付いていないものを探す。
✅ 「API で取得可能か」事前確認を行う。
データセットのダウンロード
✅ API で取得可能なデータをダウンロード
kaggle datasets download -d bahraleloom/tensorflow-speech-commands -p ./data --unzip
✅ ダウンロード完了後、フォルダの中身を確認yes/ no/ up/ down/ のフォルダがあるか確認。
Get-ChildItem -Path ./data
データの整理
もしデータが ./data/speech_commands_v0.02/ のようなサブフォルダに入っていた場合
Move-Item -Path "./data/speech_commands_v0.02/*" -Destination "./data/" -Force
✅ yes/ no/ up/ down/ を ./data/ 直下に移動。
✅ 整理後、もう一度フォルダ構成を確認
Get-ChildItem -Path ./data
🔹 Step 6: API で取得できない場合の手動対応
もし API で取得できないデータセット(yashodhogra/speech-commands)が必要なら、手動でダウンロード する。
📥 Kaggle から手動ダウンロード
- Kaggle のデータセットページへアクセス
- ブラウザから .zip をダウンロード
- PowerShell で解凍
Expand-Archive -Path "ダウンロードしたファイル" -DestinationPath "./data"
✅ 手動で .zip を展開して、フォルダを整理する。
- 最初に API で取得可能かチェック
- API で取得できるもの(
bahraleloom/tensorflow-speech-commands)を優先 - API で取得できないもの(
yashodhogra/speech-commands)は手動対応
プログラムからの動作確認
Docker コンテナを起動
まず、コンテナを立ち上げます。プロジェクトディレクトリ(D:\Programs\github\speech_processing)で以下を実行:
docker-compose up --build -d
✅ コンテナが正常に起動しているか確認
docker ps
✅ Jupyter Notebook が含まれているコンテナが Up になっていれば OK!
Jupyter Notebook を起動
コンテナ内で Jupyter Notebook を動かします。
- コンテナに接続
docker exec -it speech_processing bash
※
speech_processing_containerはdocker psで確認したコンテナ名に変更してください。
- Jupyter Notebook を起動
jupyter notebook --ip 0.0.0.0 --port=8888 --no-browser --allow-root
✅ 成功すると、以下のようなメッセージが出る
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://127.0.0.1:8888/?token=xxxxxxxxxxxxxxxxxxxxxxxxxxxx
- ブラウザで Jupyter Notebook にアクセス
http://localhost:8888/
✅ ブラウザが開かない場合、上記 URL を手動でコピー & ペースト!
🔹 ③ Jupyter Notebook 上で動作確認
📌 Notebook に以下のコードを貼り付け、データの可視化を実行
import os
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
import wave
# ✅ Kaggle から取得した音声データのパスを指定
DATA_DIR = "/app/data" # コンテナ内のデータパス(マウント先に合わせる)
sample_file = os.path.join(DATA_DIR, "yes", "0a7c2a8d_nohash_0.wav") # yes フォルダ内の音声を指定
# ✅ ファイルが存在するか確認
if not os.path.exists(sample_file):
raise FileNotFoundError(f"音声ファイルが見つかりません: {sample_file}")
# ✅ 音声ファイルをロード
y, sr = librosa.load(sample_file, sr=None)
# ✅ 波形を描画
plt.figure(figsize=(10, 4))
librosa.display.waveshow(y, sr=sr)
plt.title("Waveform")
plt.xlabel("Time (s)")
plt.ylabel("Amplitude")
plt.show()
# ✅ スペクトログラムを描画
D = librosa.amplitude_to_db(np.abs(librosa.stft(y)), ref=np.max)
plt.figure(figsize=(10, 4))
librosa.display.specshow(D, sr=sr, x_axis="time", y_axis="log")
plt.colorbar(format="%+2.0f dB")
plt.title("Spectrogram")
plt.show()
# ✅ 音声ファイルのメタ情報を取得
with wave.open(sample_file, "rb") as wav_file:
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
frame_rate = wav_file.getframerate()
num_frames = wav_file.getnframes()
duration = num_frames / frame_rate
print(f"ファイル名: {sample_file}")
print(f"チャンネル数: {num_channels}")
print(f"サンプル幅(バイト): {sample_width}")
print(f"サンプリングレート: {frame_rate} Hz")
print(f"フレーム数: {num_frames}")
print(f"音声の長さ: {duration:.2f} 秒")
表示された。OK。
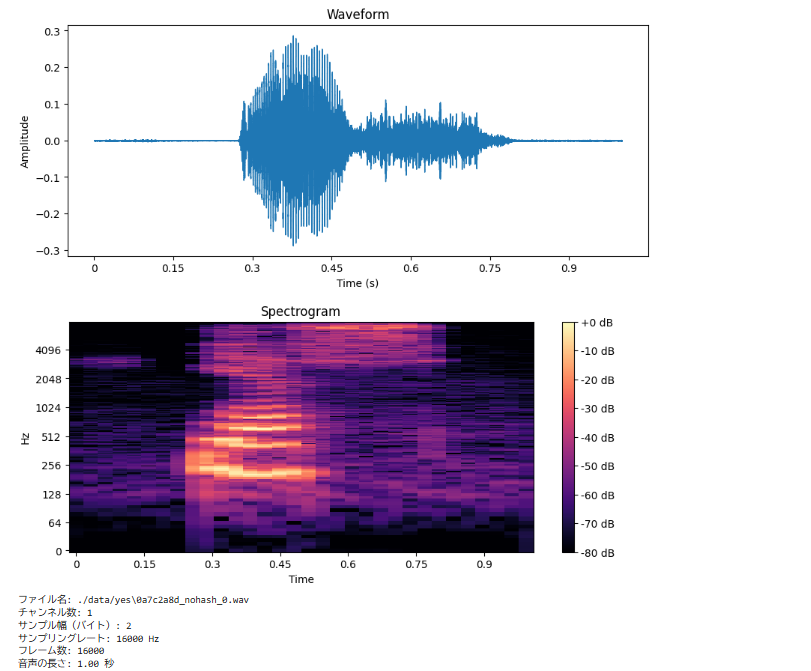
📌 ④ 実行結果を確認
- 音声波形が表示されるか?
librosa.display.waveshowで波形が描画されているかチェック
- スペクトログラムが表示されるか?
librosa.display.specshowで周波数成分が見えるか確認
- 音声のメタデータが表示されるか?
- チャンネル数(通常
1) - サンプリングレート(通常
16000 Hz) - 音声の長さ(通常
1秒前後)
- チャンネル数(通常
✅ まとめ
- Docker コンテナを起動
- Jupyter Notebook を開く
- 音声データの可視化 & メタデータ取得