◆◆ ステップ3:WAVファイルでSTT→翻訳→TTS② ◆◆
次のステップ:Azure Speech Synthesis API(TTS)の実装 に進みます
🎯 目標
✅ Azure Speech Synthesis API を使って、英語のテキストを音声に変換する
✅ 翻訳した英語テキストを TTS(Text-to-Speech) で音声出力する
✅ 音声ファイル (output.wav) を生成し、再生できるようにする
✅ 実装: text_to_speech
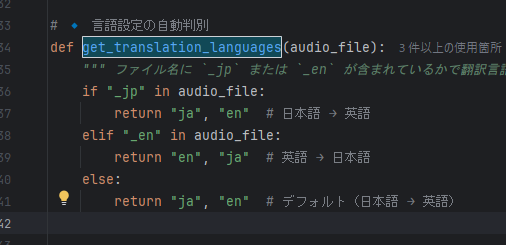
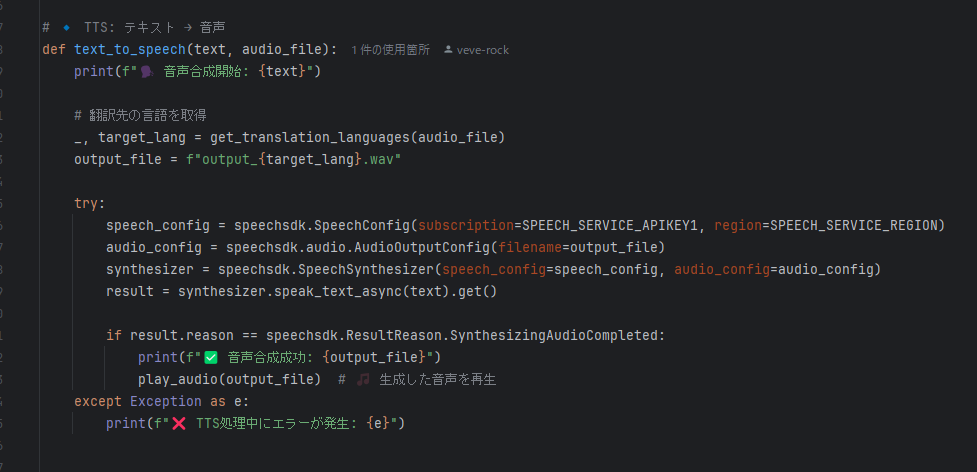
🎯 実装のポイント
✅ API_KEY_VALUE を使用(Azure Speech Synthesis API のキー)
✅ 英語のテキストを en-US-JennyNeural 音声モデルで合成(英語・日本語切替を可能とした)
✅ 生成された音声を output_jp.wav、output_en.wavとして保存
✅ エラー処理を実装(合成エラー時に詳細を表示)
📌 使い方
1️⃣ text_to_speech.py を実行
python text_to_speech.py
2️⃣ 期待される出力
✅ 音声合成成功: output.wav に保存しました。
3️⃣ output.wav を再生して、音声が正しく出力されているか確認
🚀 次のステップ
1️⃣ このコードを実行し、英語の音声合成 (output.wav) が成功するか確認
2️⃣ 音声の品質チェック(声の選択を調整可能)
3️⃣ 問題がなければ、STT → 翻訳 → TTS を統合する