基礎構文
1.基本的なデータ型
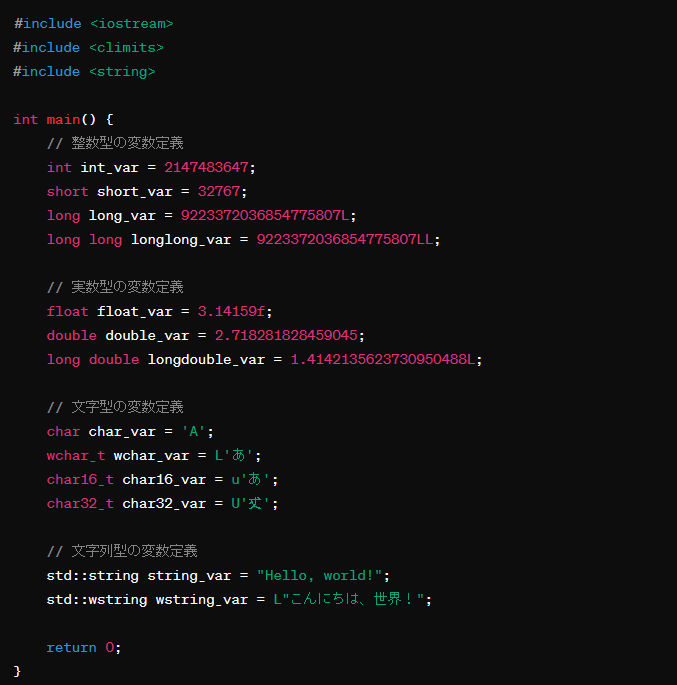
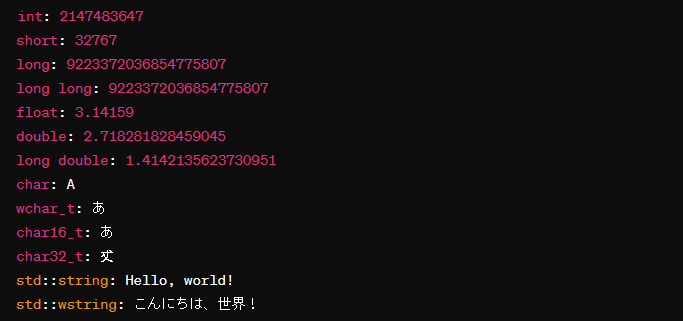
整数型
- int
- 32ビット システム上: 通常4バイト、最大値は 2の31乗から1を引いた値(2,147,483,647)
- 64ビット システム上: 通常4バイト、最大値は 2の31乗から1を引いた値(2,147,483,647)
- short
- 16ビット: 常に2バイト、最大値は 2の15乗から1を引いた値(32,767)
- long
- 32ビット システム上: 通常4バイト、最大値は 2の31乗から1を引いた値(2,147,483,647)
- 64ビット システム上: 通常8バイト、最大値は 2の63乗から1を引いた値(9,223,372,036,854,775,807)
- long long
- 64ビット: 常に8バイト、最大値は 2の63乗から1を引いた値(9,223,372,036,854,775,807)
実数型
- float
- 4バイト、精度7桁の桁数
- double
- 8バイト、約15〜16桁の桁数
- long double
- システムアーキテクチャに依存するが、通常は8バイト以上、精度はdoubleを超える
文字型
- char
- 1バイト、ASCII文字を格納するのに使用
- wchar_t
- 文字のサイズはプラットフォームに依存し、一般的には2バイトまたは4バイト、広範囲の文字を扱うのに使用される
- char16_t
- 2バイト、UTF-16エンコーディングの文字を格納するのに使用
- char32_t
- 4バイト、UTF-32エンコーディングの文字を格納するのに使用
文字列型
- std::string
char型の動的配列として機能し、ASCII文字列を格納するのに使用
- std::wstring
wchar_t型の動的配列として機能し、より広範囲の文字セットを格納するのに使用
2.演算子
算術演算子
+: 加算-: 減算*: 乗算/: 除算%: 剰余(モジュロ演算)++: インクリメント(値を1増やす)--: デクリメント(値を1減らす)
代入演算子
=: 値を代入+=: 加算して代入-=: 減算して代入*=: 乗算して代入/=: 除算して代入%=: 剰余をとって代入&=: ビットANDして代入|=: ビットORして代入^=: ビットXORして代入<<=: 左シフトして代入>>=: 右シフトして代入
比較演算子
==: 等価!=: 非等価<: より小さい>: より大きい<=: 以下>=: 以上
論理演算子
&&: 論理AND||: 論理OR!: 論理NOT
ビット演算子
&: ビットAND|: ビットOR^: ビットXOR~: ビットNOT<<: 左シフト>>: 右シフト
その他の演算子
sizeof: データ型またはオブジェクトのサイズを取得typeid: オブジェクトの型情報を取得?:: 条件演算子(三項演算子),: カンマ演算子(式を左から順に評価し、最後の式の結果を返す)->: メンバアクセス演算子(ポインタを通じてクラスや構造体のメンバにアクセス).: ドット演算子(オブジェクトを通じてクラスや構造体のメンバにアクセス)new: 動的メモリ確保delete: 動的メモリ解放&(アドレス取得): オブジェクトのメモリアドレスを取得*(間接参照): ポインタが指すアドレスのオブジェクトを参照
キャスト演算子
static_cast: コンパイル時の型変換dynamic_cast: 実行時の安全なダウンキャストconst_cast: const修飾子を追加または除去reinterpret_cast: ほとんどの型にキャスト可能
演算子オーバーロード
- C++ではユーザーが定義した型に対して既存の演算子を新たな意味で利用できるようにする演算子オーバーロードが可能です。
3.制御構造
条件文
- if文
- 特定の条件が真の場合に、コードブロックを実行します。
if,else if,elseのキーワードを使用します。
- switch文
- ある変数の値に基づいて、多くの分岐から実行するケースを選択します。
switch,case,default,breakのキーワードを使用します。
ループ
- whileループ
- 条件が真である間、コードブロックを繰り返し実行します。
- do-whileループ
- 最低一回はコードブロックを実行し、その後条件が真である間、繰り返し実行します。
- forループ
- 初期化、条件、イテレーションを含む繰り返しを提供します。
- 範囲ベースのforループ(C++11以降)は、コンテナの各要素に対してループを行います。
ジャンプ文
- break文
- ループやswitch文から脱出するために使用します。
- continue文
- ループの現在の反復をスキップし、次の反復に進みます。
- goto文
- プログラム内の指定されたラベルへジャンプします。多用は避けるべきです。
例外処理
- try-catchブロック
- コードを実行し、例外が発生した場合にそれを捕捉し処理します。
- throw文
- 例外を発生させるために使用します。
- catchブロック
- 特定の型の例外を捕捉し、それに対するコードを実行します。
その他の制御構造
- 関数の早期リターン
- 関数からの早期脱出を行いたい場合に
return文を使用します。
- 関数からの早期脱出を行いたい場合に
- 条件演算子(三項演算子)
条件 ? 真の場合の値 : 偽の場合の値という形で、簡単な条件に基づいた値の選択を行います。
4.関数
関数とヘッダファイル
ヘッダファイルは主に関数の宣言(プロトタイプ)、クラスの宣言、テンプレートの宣言、インライン関数、マクロ定義などのために使います。これらはプログラムのインターフェイスを構成し、複数のソースファイルから共有される可能性があります。
関数の宣言(ヘッダファイルでの役割)
- 宣言: 関数の名前、戻り値の型、引数の型を定義しますが、実際の動作は記述しません。
- インクルードガード: 重複インクルードを防ぐために、
#ifndef,#define,#endifを使ったガードが必要です。 - インライン関数: 実装が短い関数はヘッダファイル内にインライン関数として記述することがあります。
- テンプレート宣言: テンプレート関数やクラスの宣言はヘッダファイルに書きます。
関数の定義(ソースファイルでの役割)
- 定義: 宣言された関数の具体的な動作やアルゴリズムを記述します。
- テンプレートのインスタンス化: テンプレート関数の具体的な型に対する定義を提供する場合があります。
注意点
- ワンデフィニションルール
同じ関数が複数のソースファイルで定義されていると、リンカエラーの原因になります。 - オーバーロードとオーバーライド
関数のオーバーロード(同名で異なるシグネチャ)と
オーバーライド(派生クラスでの基底クラス関数の再定義)を正しく理解し使用する必要があります。 - 依存関係の管理
ソースファイルとヘッダファイル間の依存関係を適切に管理するために
フォワード宣言を利用することがあります。
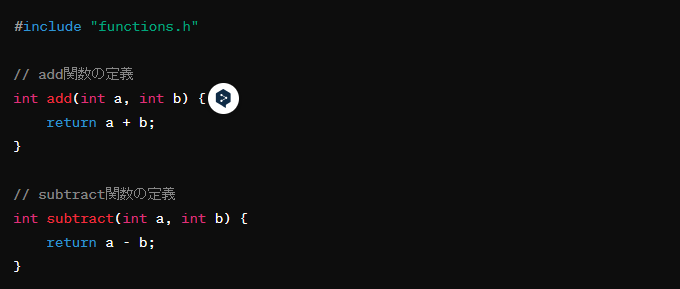
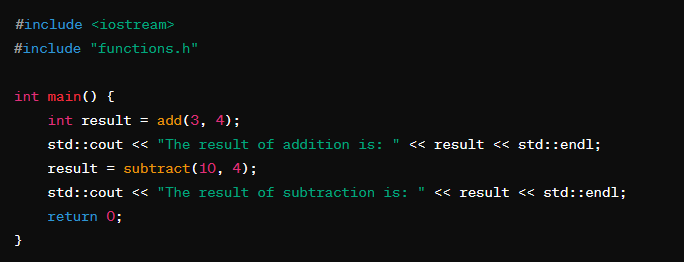
サンプルソースコード
このコード例では、functions.hヘッダファイルにaddとsubtract関数のプロトタイプが宣言されています。実際の関数の定義はfunctions.cppソースファイルにあり、これらの関数をmain.cppから使用しています。コンパイルとリンクのプロセスでは、これら3つのファイルを共にコンパイルして実行可能ファイルを生成します。
ヘッダファイル(functions.h)

ソースファイル(functions.cpp)
メインソースファイル(main.cpp)
5.配列と文字列
C++で配列を扱う際の基本的なポイントや注意点
C++では数値配列、文字列(std::string)、Cスタイルの文字配列(Char文字列)など
データ型で配列を使用することができます。
数値配列
数値型(int, doubleなど)の配列は、以下のように宣言します。

std::string 配列
std::string型の配列を使う場合は、以下のように宣言できます。

これは動的な文字列操作が可能で、実行時にサイズ変更や内容の変更が容易に行えます。
適したケース
- 動的に変更可能な文字列が必要な場合。
- 文字列操作(連結、検索、置換など)が頻繁に発生する場合。
- 文字列の長さが実行時に変わる可能性がある場合。
Cスタイルの文字配列(Char文字列)
Cスタイルの文字配列は、null文字(’\0’)で終端される必要があります。
これは文字列の終わりを示すためのものです。


適したケース
- C言語との互換性が必要な場合。
- システムプログラミングや組み込みプログラミングでメモリの細かな制御が必要な場合。
- パフォーマンスが非常に重要で、メモリの割り当てやコピーを最小限に抑えたい場合。
注意点と考慮すべき点
配列の範囲外アクセス
配列のサイズを超えてアクセスしようとすると、未定義の挙動を引き起こす可能性があります。
範囲チェックを行うか、std::arrayやstd::vectorのようなコンテナを使用することを検討してください。
★配列の初期化(重要)
C++では配列を宣言する際に初期化しないと、不定の値が入ることがあります。
可能な限り初期化を行うようにしましょう。
Cスタイル文字列の取り扱い
Cスタイルの文字列はnull文字で終端する必要があります。
また、strcpyやstrcatなどの関数を使用する際にはバッファオーバーフローに注意が必要です。
配列のコピー: C++の配列は直接コピーできません(ポインタのコピーになる)。
配列の内容を別の配列にコピーするには、要素ごとにコピーするループが必要です。
6.ポインタ
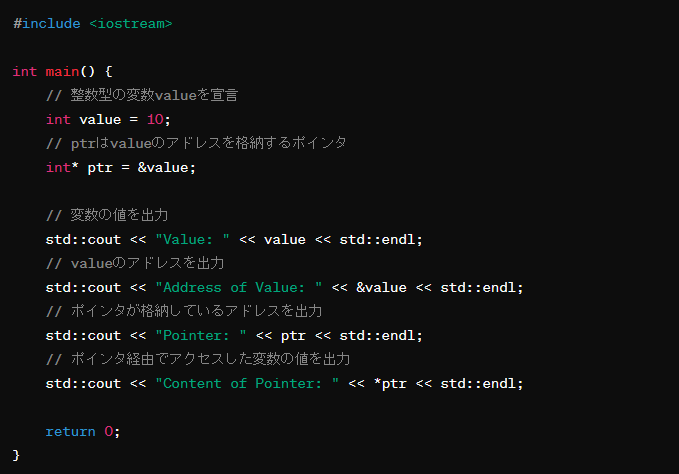

- ポインタは変数のメモリアドレスを格納します。
- ポインタを通じて、そのアドレスにある値を読み書きすることができます。
- ポインタは
nullptrで初期化することができ、安全に未割り当て状態を表現できます。 - ポインタの値(アドレス)を変更することで、指し示す先を変えることが可能です。
参照
- 参照は別の変数を別名(エイリアス)として指します。
- 参照は常に何かを参照し、
nullptrで初期化することはできません。 - 参照が一度初期化されると、その生存期間中は別のものを参照することはできません。
整理
- value : 変数の実際の値。
- &value : 変数
valueのメモリアドレス。 - ptr :
valueのアドレスを格納するポインタ変数。 - *ptr : ポインタ
ptrが指し示すアドレスにある値(valueの値)。
ポインタと参照は、それぞれの使い方と制限が異なるため、使用するシナリオに応じて適切に選択する必要があります。ポインタはより柔軟であり、生のメモリ操作や動的なメモリ管理などに使われますが、誤用するとバグやセキュリティリスクの原因となることもあります。一方、参照はより安全で直感的に使えることが多く、関数の引数や戻り値として特に便利です。
7.構造体
構造体の基本
構造体は以下のように定義し、使用します。
ローカル変数として構造体を定義

new キーワードを使用して動的にメモリを確保

メモリの確保と解放
スタックメモリ
ローカル変数として構造体を定義すると、そのメモリは自動的に確保され
スコープを抜けると自動的に解放されます。
ヒープメモリ
new キーワードを使用して動的にメモリを確保する場合は、使用後に delete を用いて
手動でメモリを解放する必要があります。
スタックメモリについて
スタックメモリは、関数の呼び出しとローカル変数の管理に使用されるメモリ領域です。このメモリ領域は、関数が呼び出されるたびにその関数のためのフレームがプッシュされ、関数が終了するとそのフレームがポップされる「Last In, First Out(LIFO)」の原則に従って動作します。スタックメモリは以下の特徴を持っています:
- 自動管理:スタックメモリはコンパイラによって自動的に管理され、関数の実行が終了すると自動的に解放されます。
- 高速アクセス:スタックはその構造上、アクセスが非常に高速です。
- サイズ制限:スタックメモリはサイズが固定されており、多くのシステムでは比較的小さいです。大量のデータや可変サイズのデータを扱う場合、スタックオーバーフローのリスクがあります。
- スコープと寿命:スタック上のデータはそのデータを持つ関数が活動している間のみ存続します。
ヒープメモリについて
ヒープメモリは、プログラマが手動で管理するメモリ領域で、動的に確保(割り当て)されます。ヒープメモリは以下の特徴を持っています:
- 動的確保:
newやmalloc()などの関数を使って実行時にメモリを確保します。 - 大規模データ管理:ヒープはスタックよりもはるかに大きいため、大きなデータセットや動的にサイズが変わるデータ構造に適しています。
- 手動解放が必要:ヒープメモリは自動で解放されないため、使用後に
deleteやfree()を使って手動でメモリを解放する必要があります。 - 断片化のリスク:頻繁にメモリを確保・解放することでメモリ断片化が起こり、パフォーマンスの低下やメモリの無駄遣いが発生する可能性があります。
- アクセス速度:スタックに比べるとアクセス速度は遅いですが、大量のデータや長期間存続させるデータには適しています。
比較と使い分け
- スタックは高速であり、関数のローカル変数や小さなデータ構造に適しています。
- ヒープは柔軟性が高く、ライフサイクルが長いまたはサイズが大きなデータに適しています。
プログラミングでは、これらのメモリの特性を理解し、アプリケーションの要件に応じて適切なメモリ領域を選択することが重要です。
8.例外処理
tryブロック
プログラムの特定の部分を実行し、例外が発生する可能性がある場所を囲みます。例外が発生した場合、制御はtryブロック内で最も近いcatchハンドラに渡されます。

catchブロック
特定の型の例外を捕捉し、例外オブジェクトを処理するコードを含みます。複数のcatchブロックを並べて、異なる型の例外を異なる方法で処理することができます。

throw
例外を発生させ、現在の関数から制御をtryブロックに移すために使用します。throwに続けて、投げる例外オブジェクトを指定します。

例外安全性
コードは、例外が投げられたときにも、リソースの漏洩やデータの破壊が起きないように書くべきです。これを「例外安全性」といいます。
スタックアンワインディング
例外が投げられたとき、C++は例外が捕捉されるcatchブロックが見つかるまでスタックをアンワインド(巻き戻し)します。この過程でローカルオブジェクトのデストラクタが順に呼び出され、リソースが適切に解放されます。
ネストされたtry-catchブロック
tryブロックの中にさらにtryブロックを書くことで、複数レベルのエラー処理を実現できます。
例外クラスの継承
独自の例外クラスを定義し、既存の例外クラスから派生させることで、エラータイプに応じた例外処理が行えます。