目次
音声特徴量の抽出と可視化
1 音声特徴量の抽出と可視化
前回は 音声データの読み込みと波形・スペクトログラムの可視化 を行いました。
今回は 音声特徴量の抽出 を行い、データの数値化と可視化を進めます。
目的
- 音声特徴量の抽出とは何かを理解する
- Kaggleのデータから以下の特徴量を抽出する
- MFCC(メル周波数ケプストラム係数)
- ゼロ交差率(Zero Crossing Rate)
- スペクトルセントロイド(Spectral Centroid)
- RMSエネルギー(RMS Energy)
- スペクトルバンド幅(Spectral Bandwidth)
- 特徴量をプロットし、可視化する
- 特徴量を数値データとして保存する
2 音声特徴量の基礎
音声データはそのままだと機械学習に使用できません。
そのため、以下の特徴量を抽出し、数値データとして利用できるようにします。
| 特徴量 | 説明 |
|---|---|
| MFCC(Mel-Frequency Cepstral Coefficients) | 人間の聴覚特性に近い周波数スケールで特徴を抽出する手法 |
| ゼロ交差率(Zero Crossing Rate) | 波形がゼロを跨ぐ回数(音の変化の激しさを示す) |
| スペクトルセントロイド(Spectral Centroid) | 周波数成分の重心(音の明るさを示す) |
| RMSエネルギー(RMS Energy) | 音のエネルギー(音量の大きさを示す) |
| スペクトルバンド幅(Spectral Bandwidth) | セントロイド周辺の周波数成分の広がり(音の複雑さを示す) |
3 音声特徴量の計算と可視化
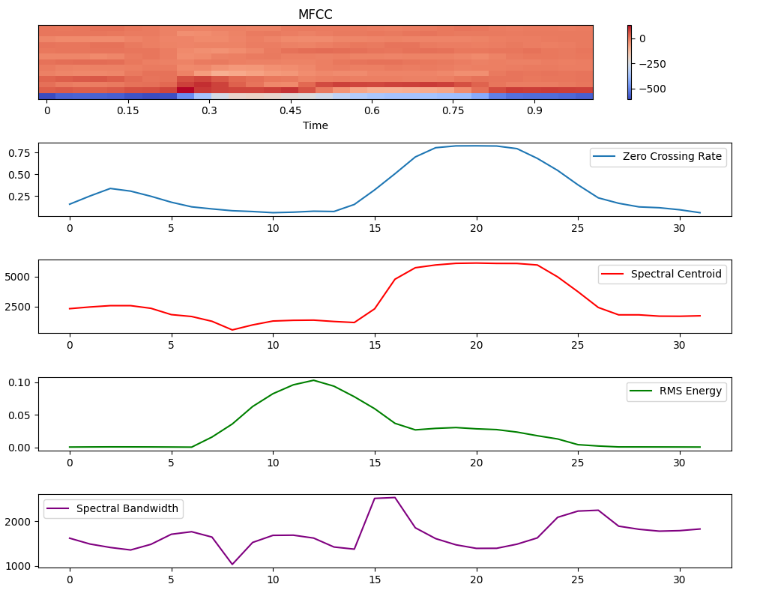
以下のコードを実行することで、特徴量を抽出し、可視化することができます。
import os
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
# Kaggle から取得した音声データのパスを指定
DATA_DIR = "./data"
sample_file = os.path.join(DATA_DIR, "yes", "0a7c2a8d_nohash_0.wav") # yes フォルダ内の音声を指定
# 音声ファイルをロード
y, sr = librosa.load(sample_file, sr=None)
# 各特徴量を計算
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13) # MFCC(13次元)
zcr = librosa.feature.zero_crossing_rate(y) # ゼロ交差率
centroid = librosa.feature.spectral_centroid(y=y, sr=sr) # スペクトルセントロイド
rms = librosa.feature.rms(y=y) # RMSエネルギー
bandwidth = librosa.feature.spectral_bandwidth(y=y, sr=sr) # スペクトルバンド幅
# 特徴量をプロット
plt.figure(figsize=(10, 8))
plt.subplot(5, 1, 1)
librosa.display.specshow(mfccs, x_axis="time", sr=sr)
plt.colorbar()
plt.title("MFCC")
plt.subplot(5, 1, 2)
plt.plot(zcr[0], label="Zero Crossing Rate")
plt.legend()
plt.subplot(5, 1, 3)
plt.plot(centroid[0], label="Spectral Centroid", color="r")
plt.legend()
plt.subplot(5, 1, 4)
plt.plot(rms[0], label="RMS Energy", color="g")
plt.legend()
plt.subplot(5, 1, 5)
plt.plot(bandwidth[0], label="Spectral Bandwidth", color="purple")
plt.legend()
plt.tight_layout()
plt.show()
音声特徴量の保存
抽出した音声特徴量を CSV ファイル や NumPy配列(.npy) に保存する方法を説明します。
これにより、機械学習の学習データとして利用できるようになります。
1. CSV形式で保存する
CSV形式で保存すると、ExcelやPandasで簡単に確認できます。
import pandas as pd
# 保存するデータを辞書形式で作成
feature_data = {
"MFCC1": mfccs[0],
"MFCC2": mfccs[1],
"MFCC3": mfccs[2],
"MFCC4": mfccs[3],
"MFCC5": mfccs[4],
"MFCC6": mfccs[5],
"MFCC7": mfccs[6],
"MFCC8": mfccs[7],
"MFCC9": mfccs[8],
"MFCC10": mfccs[9],
"MFCC11": mfccs[10],
"MFCC12": mfccs[11],
"MFCC13": mfccs[12],
"Zero_Crossing_Rate": zcr[0],
"Spectral_Centroid": centroid[0],
"RMS_Energy": rms[0],
"Spectral_Bandwidth": bandwidth[0],
}
# Pandas DataFrame に変換
df = pd.DataFrame(feature_data)
# CSVファイルとして保存
csv_path = os.path.join(DATA_DIR, "features.csv")
df.to_csv(csv_path, index=False)
print(f"✅ 音声特徴量をCSVとして保存しました: {csv_path}")
2. NumPy配列(.npy)で保存する
NumPy形式で保存すると、Pythonのプログラムからすぐに読み込める。
# NumPy配列として保存
npy_path = os.path.join(DATA_DIR, "features.npy")
np.save(npy_path, mfccs)
print(f"✅ 音声特徴量をNumPy配列(.npy)として保存しました: {npy_path}")
3. 保存したデータの確認
保存したデータを 再度読み込んで確認 できます。
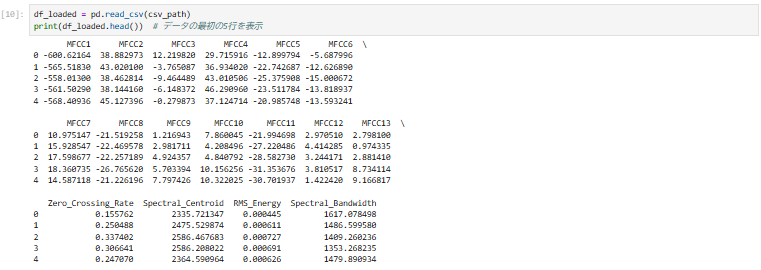
CSVを読み込む
df_loaded = pd.read_csv(csv_path)
print(df_loaded.head()) # データの最初の5行を表示
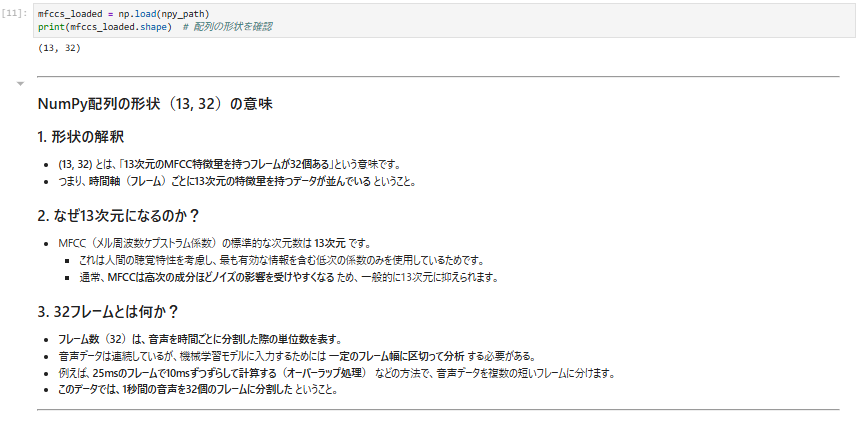
NumPy配列を読み込む
mfccs_loaded = np.load(npy_path)
print(mfccs_loaded.shape) # 配列の形状を確認

ラベルデータも必要らしいので追加
import numpy as np
import os
# ✅ ラベルデータ(例えば yes/no を 0,1 に変換して保存する例)
labels = ["yes", "no", "up", "down", "left", "right", "on", "off", "stop", "go"]
label_dict = {label: i for i, label in enumerate(labels)}
# ✅ すでにデータがある `DATA_DIR` を使用
DATA_DIR = "./data"
# ✅ 音声データのフォルダ名を取得し、それをラベルとして使用
data_folders = [f for f in os.listdir(DATA_DIR) if os.path.isdir(os.path.join(DATA_DIR, f))]
# ✅ フォルダ名(ラベル)を数値に変換
labels_array = np.array([label_dict[label] for label in data_folders if label in label_dict])
# ✅ ラベルデータを NumPy 配列として保存
labels_path = os.path.join(DATA_DIR, "labels.npy")
np.save(labels_path, labels_array)
print(f"✅ ラベルデータを保存しました: {labels_path}")
4. 今後の流れ
- 複数の音声ファイルに対して特徴量を計算 し、データセットを作成する
- 保存した特徴量を用いて機械学習モデルを構築 する
1つのファイルで特徴量が保存・再利用できることを確認 した。