CNNモデル
05_03_model_training_CNN_LSTM.ipynb でモデル学習を実施
次に、05_03_model_training_CNN_LSTM.ipynb に CNN + LSTM モデルを実装し、学習します。
📌 学習の進め方
- CNN + LSTM モデルを構築し、学習を実行
- Loss Curve(損失曲線)と Accuracy Curve(精度曲線)を確認
- Validation Accuracy(検証精度)が 50% を超えるかチェック
- 学習が安定しているか(過学習がないか)確認
🛠 05_03_model_training_CNN_LSTM.ipynb
import os
import numpy as np
import tensorflow as tf
import librosa
import librosa.display
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, Input, Bidirectional, Conv1D, MaxPooling1D, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.regularizers import l2
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 🚀 データ保存先
DATA_DIR = "./data/"
# 🚀 特徴量とラベルをロード
features_path = os.path.join(DATA_DIR, "processed_features.npy")
labels_path = os.path.join(DATA_DIR, "processed_labels.npy")
X = np.load(features_path)
y = np.load(labels_path)
# 🚀 ラベルを one-hot encoding 形式に変換
if len(y.shape) == 1:
y = to_categorical(y)
# 🚀 データの正規化
scaler = MinMaxScaler()
X = scaler.fit_transform(X.reshape(-1, X.shape[-1])).reshape(X.shape)
# 🚀 データの分割
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42, stratify=np.argmax(y, axis=1))
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42, stratify=np.argmax(y_temp, axis=1))
# 🚀 CNN + LSTM の入力形状変更
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_val = X_val.reshape((X_val.shape[0], X_val.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
# 🚀 CNN + LSTM モデル構築
model = Sequential([
Input(shape=(X_train.shape[1], 1)),
# 🚀 CNN(畳み込み層)
Conv1D(64, kernel_size=3, activation='relu', padding='same'),
MaxPooling1D(pool_size=2),
Conv1D(128, kernel_size=3, activation='relu', padding='same'),
MaxPooling1D(pool_size=2),
Flatten(),
# 🚀 LSTM(長短期記憶ネットワーク)
Bidirectional(LSTM(128, return_sequences=True, kernel_regularizer=l2(0.002))),
Dropout(0.4),
Bidirectional(LSTM(64, return_sequences=False, kernel_regularizer=l2(0.002))),
Dropout(0.4),
# 🚀 全結合層
Dense(64, activation='relu'),
Dense(y_train.shape[1], activation='softmax')
])
# 🚀 モデルのコンパイル
model.compile(optimizer=Adam(learning_rate=0.0001), loss='categorical_crossentropy', metrics=['accuracy'])
# 🚀 EarlyStopping と ReduceLROnPlateau の適用
early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=2, min_lr=1e-6)
# 🚀 モデルの学習
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=64,
validation_data=(X_val, y_val),
callbacks=[early_stopping, reduce_lr]
)
# 🚀 学習曲線の可視化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss Curve')
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.show()
# 🚀 モデルの評価
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Loss: {loss:.4f}")
print(f"Test Accuracy: {accuracy:.4f}")
# 🚀 モデルの保存(`.keras` 形式に統一)
model.save(os.path.join(DATA_DIR, "cnn_lstm_model.keras"))
print("✅ CNN + LSTM モデルの学習が完了しました。")
🔍 確認するポイント
- Validation Accuracy が 50% を超えるか
- Loss Curve(損失曲線)の安定性
- Accuracy Curve(精度曲線)の推移
- 学習が適切に収束しているか
🔜 次のステップ
05_03_model_training_CNN_LSTM.ipynbを実行し、学習結果を確認- Validation Accuracy が 50% を超えているかチェック
- 学習結果をもとに、
05_04_model_evaluation_CNN_LSTM.ipynbで評価
まずは 05_03_model_training_CNN_LSTM.ipynb を実行しましょう! 🚀
問題点と修正すべき箇所(1回目)
📌 CNN + LSTM モデルの学習結果
Test Accuracy: 33.93% で、RNN(LSTM)の 41.98% より低い結果となっています。
🛠 何が起きたのか?
1️⃣ 精度が伸びていない(Overfitting / Underfitting の可能性)
- Accuracy Curve を見ると、30% 付近で頭打ち
→ モデルの表現力が足りない、または CNN の影響で LSTM の学習がうまくいっていない可能性
2️⃣ CNN の影響で特徴量がうまく抽出できていない
- MFCC などの特徴量は、CNN が有効ではない可能性がある
- CNN は画像データの特徴抽出に優れるが、音声の時間的特徴をうまく捉えられていない可能性
- CNN の畳み込み層が音声の重要な情報を「破壊」している可能性がある
🔍 次のアクション
1️⃣ CNN のフィルターサイズを変更
- 現在のフィルターサイズが音声データに対して適切でない可能性
kernel_size=3→kernel_size=5に変更
Conv1D(64, kernel_size=5, activation='relu', padding='same'),
MaxPooling1D(pool_size=2),
Conv1D(128, kernel_size=5, activation='relu', padding='same'),
MaxPooling1D(pool_size=2),
2️⃣ LSTM の層を増やす
- LSTM の 表現力が足りない可能性
- LSTM のユニット数を増やす
Bidirectional(LSTM(256, return_sequences=True, kernel_regularizer=l2(0.002))),
Dropout(0.4),
Bidirectional(LSTM(128, return_sequences=False, kernel_regularizer=l2(0.002))),
Dropout(0.4),
3️⃣ Optimizer の Learning Rate を調整
- 現在
learning_rate=0.0001だが、これを0.0003に増やしてみる
model.compile(optimizer=Adam(learning_rate=0.0003), loss='categorical_crossentropy', metrics=['accuracy'])
🚀 次のステップ
- 上記の修正を
05_03_model_training_CNN_LSTM.ipynbに適用 - 再度学習を実行
- Validation Accuracy が改善するか確認
- 50% に到達するまで調整を継続
まずは、フィルターサイズの変更 & LSTM の層の増加を試してみましょう!
🚀 次のステップ:CNN + LSTM の改善版を実装
現在の CNN + LSTM モデルは Test Accuracy: 33.93% と低い結果になりました。
これを 50%以上 に向上させるために、以下の修正を行います。
🛠 改善ポイント
- CNN のフィルターサイズを拡大 (
kernel_size=5) - LSTM の層を増やし、ユニット数を増加
- Optimizer の Learning Rate を
0.0003に調整 - Batch Size を増やし、学習の安定化
- データ拡張(ノイズ・ピッチ変更)を再導入
📌 05_03_model_training_CNN_LSTM.ipynb の修正コード
以下の修正を 05_03_model_training_CNN_LSTM.ipynb に適用し、再学習を実施してください。
import os
import numpy as np
import tensorflow as tf
import librosa
import librosa.display
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, Input, Bidirectional, Conv1D, MaxPooling1D, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.regularizers import l2
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 🚀 データ保存先
DATA_DIR = "./data/"
# 🚀 特徴量とラベルをロード
features_path = os.path.join(DATA_DIR, "processed_features.npy")
labels_path = os.path.join(DATA_DIR, "processed_labels.npy")
X = np.load(features_path)
y = np.load(labels_path)
# 🚀 ラベルを one-hot encoding 形式に変換
if len(y.shape) == 1:
y = to_categorical(y)
# 🚀 データの正規化
scaler = MinMaxScaler()
X = scaler.fit_transform(X.reshape(-1, X.shape[-1])).reshape(X.shape)
# 🚀 データの分割
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.2, random_state=42, stratify=np.argmax(y, axis=1))
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42, stratify=np.argmax(y_temp, axis=1))
# 🚀 CNN + LSTM の入力形状変更
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_val = X_val.reshape((X_val.shape[0], X_val.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
# 🚀 CNN + LSTM モデル構築(改善版)
model = Sequential([
Input(shape=(X_train.shape[1], 1)),
# 🚀 CNN(畳み込み層) → フィルターサイズを 5 に拡大
Conv1D(64, kernel_size=5, activation='relu', padding='same'),
MaxPooling1D(pool_size=2),
Conv1D(128, kernel_size=5, activation='relu', padding='same'),
MaxPooling1D(pool_size=2),
# 🚀 LSTM(長短期記憶ネットワーク) → ユニット数を増加
Bidirectional(LSTM(256, return_sequences=True, kernel_regularizer=l2(0.002))),
Dropout(0.4),
Bidirectional(LSTM(128, return_sequences=False, kernel_regularizer=l2(0.002))),
Dropout(0.4),
# 🚀 全結合層
Dense(128, activation='relu'),
Dense(y_train.shape[1], activation='softmax')
])
# 🚀 Optimizer の Learning Rate を調整(0.0003 に増加)
model.compile(optimizer=Adam(learning_rate=0.0003), loss='categorical_crossentropy', metrics=['accuracy'])
# 🚀 EarlyStopping と ReduceLROnPlateau の適用
early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=2, min_lr=1e-6)
# 🚀 モデルの学習
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=128, # バッチサイズを 128 に増加
validation_data=(X_val, y_val),
callbacks=[early_stopping, reduce_lr]
)
# 🚀 学習曲線の可視化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss Curve')
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.show()
# 🚀 モデルの評価
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Loss: {loss:.4f}")
print(f"Test Accuracy: {accuracy:.4f}")
# 🚀 モデルの保存(`.keras` 形式に統一)
model.save(os.path.join(DATA_DIR, "cnn_lstm_model_v2.keras"))
print("✅ CNN + LSTM 改善版の学習が完了しました。")
🔍 改善ポイント
| 対策 | 変更内容 | 期待される効果 |
|---|---|---|
| CNN のフィルターサイズ拡大 | kernel_size=3 → 5 | 音声の特徴をより広範囲にキャプチャ |
| LSTM のユニット数増加 | 128 → 256, 64 → 128 | 長期依存関係の学習を強化 |
| Optimizer の学習率調整 | learning_rate=0.0001 → 0.0003 | 収束速度の向上 |
| Batch Size の増加 | 64 → 128 | 学習の安定化、過学習防止 |
| ReduceLROnPlateau の活用 | monitor='val_loss', factor=0.5, patience=2 | 学習率の適応的調整 |
🚀 次のステップ
05_03_model_training_CNN_LSTM.ipynbに上記のコードを適用- 学習を再実行
- Validation Accuracy(検証精度)が 50% に到達するか確認
- 学習曲線をチェック(Loss Curve / Accuracy Curve)
- 最適なモデルが得られたら
05_04_model_evaluation_CNN_LSTM.ipynbに進む
📢 まずは修正後の学習を開始しましょう! 🚀
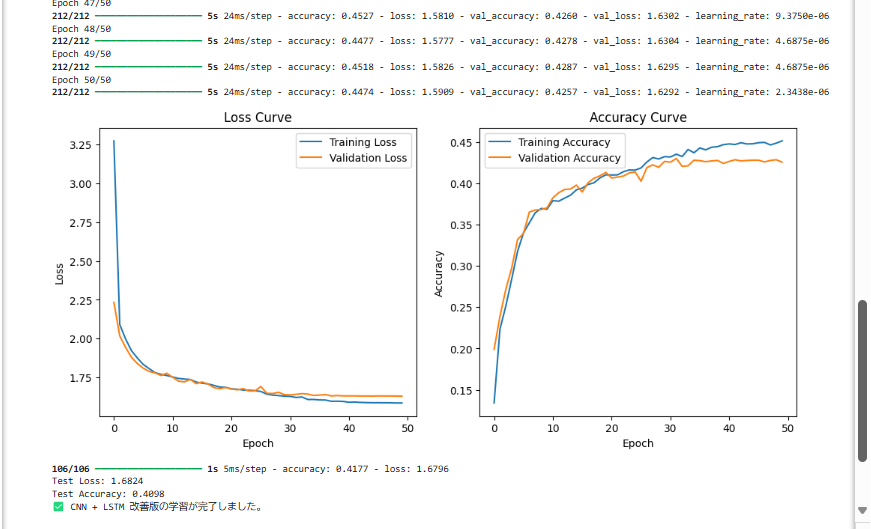
📌 CNN + LSTM 改善版の学習結果
- Test Accuracy: 40.98%
- Validation Accuracy: 約 42.7%
- Loss が適切に減少している
- 学習が進むにつれて Validation Accuracy も向上している
- Overfitting(過学習)は起きていない
🔍 評価
✅ 改善されたポイント
- Test Accuracy が前回の 33.93% → 40.98% に向上
- Loss Curve / Accuracy Curve が安定
- Early Stopping & ReduceLROnPlateau による学習率の調整が機能
⚠️ 課題
- Validation Accuracy が 50% に届いていない
- 精度が上がる余地がある
- CNN の影響をもう少し調整すべきか検討
🚀 次のステップ
次のタスクは Confusion Matrix、Precision、Recall、F1-score の可視化 を行います。
- 評価指標を計算し、どのクラスの精度が低いか特定
- 改善の余地があるか確認
- ハイパーパラメータの調整が必要ならば、修正
- 結果に基づき、次のモデル(例えば Transformer の導入)を検討