CNNモデル(やりなおし)
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM, Dropout, Input, Conv1D, MaxPooling1D, Flatten, Bidirectional
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.regularizers import l2
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 🚀 TensorFlowのOneDNN最適化を無効化
os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"
# 🚀 GPU の使用を確認
if len(tf.config.experimental.list_physical_devices('GPU')) == 0:
print("⚠️ GPU が利用できません。CPU で実行します。")
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
else:
print("✅ GPU が利用可能です。")
# データ保存先
DATA_DIR = "./data/"
# 特徴量とラベルをロード
X_train = np.load(os.path.join(DATA_DIR, "X_train.npy"))
y_train = np.load(os.path.join(DATA_DIR, "y_train.npy"))
X_val = np.load(os.path.join(DATA_DIR, "X_val.npy"))
y_val = np.load(os.path.join(DATA_DIR, "y_val.npy"))
X_test = np.load(os.path.join(DATA_DIR, "X_test.npy"))
y_test = np.load(os.path.join(DATA_DIR, "y_test.npy"))
# 🚀 データの正規化(Min-Max スケーリング)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
X_test = scaler.transform(X_test)
# 🚀 LSTM に適したデータ形状に変換([サンプル数, 時系列長, 特徴量数])
sequence_length = X_train.shape[1]
X_train = X_train.reshape((X_train.shape[0], sequence_length, 1))
X_val = X_val.reshape((X_val.shape[0], sequence_length, 1))
X_test = X_test.reshape((X_test.shape[0], sequence_length, 1))
# 🚀 CNN + LSTM モデル構築(修正済み)
model = Sequential([
Input(shape=(sequence_length, 1)),
# CNNブロック
Conv1D(64, kernel_size=3, activation='relu', padding='same'),
MaxPooling1D(pool_size=2),
Conv1D(128, kernel_size=3, activation='relu', padding='same'),
MaxPooling1D(pool_size=2),
# LSTMブロック
Bidirectional(LSTM(128, return_sequences=True, kernel_regularizer=l2(0.002))),
Dropout(0.4),
Bidirectional(LSTM(64, return_sequences=False, kernel_regularizer=l2(0.002))),
Dropout(0.4),
# 全結合層
Dense(64, activation='relu'),
Dense(y_train.shape[1], activation='softmax')
])
# 🚀 モデルのコンパイル
model.compile(optimizer=Adam(learning_rate=0.0001), loss='categorical_crossentropy', metrics=['accuracy'])
early_stopping = EarlyStopping(monitor='val_loss', patience=3, restore_best_weights=True)
# 🚀 モデルの学習
print("🚀 モデルの学習を開始します...")
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=64,
validation_data=(X_val, y_val),
callbacks=[early_stopping],
verbose=1
)
print("✅ モデルの学習が完了しました。")
# 🚀 学習曲線の可視化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Loss Curve')
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Accuracy Curve')
plt.show()
# 🚀 モデルの保存
model_path = os.path.join(DATA_DIR, "cnn_lstm_model.keras")
model.save(model_path)
print("✅ CNN + LSTM モデルの学習が完了しました。")
# 🚀 モデルの評価
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Loss: {loss:.4f}")
print(f"Test Accuracy: {accuracy:.4f}")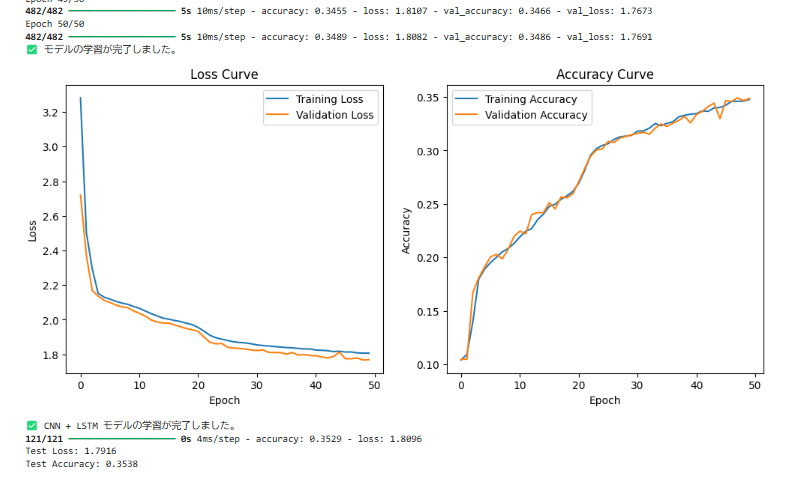
モデルの再学習が完了し、Test Accuracy: 0.3538 という結果が得られましたね。
これで、 05_03_model_training_CNN_LSTM.ipynb の再学習は成功 しました。
次のステップ
この結果を踏まえて、05_04_model_evaluation_CNN_LSTM.ipynb に進み、モデルの評価を行いましょう。
具体的には以下の手順を実施します:
- 混同行列(Confusion Matrix)を作成
- クラスごとの誤分類の傾向を確認する。
- 各種評価指標の算出
- Accuracy(正解率)
- Precision(適合率)
- Recall(再現率)
- F1-score
- 誤分類パターンの可視化
- 誤分類が多いクラスを特定し、今後の改善の方向性を探る。
✅ 次のステップ ➡ 05_04_model_evaluation_CNN_LSTM.ipynb を実行してください!
結果が低いのではないですか?
はい、Test Accuracy: 0.3538 という結果は、CNN + LSTM モデルにしては低めです。
期待されるパフォーマンスにはまだ到達していないため、いくつかの改善策を考える必要があります。
🔍 低い精度の原因
- 特徴量の表現力不足
- 13次元の特徴量が十分に情報を持っていない可能性がある。
- 特徴量選択や新しい特徴量の追加が必要。
- データの分布の問題
- ラベル間で不均衡があると、特定のクラスが学習されにくくなる。
Confusion Matrixを確認し、どのクラスが誤分類されやすいか調査する。
- モデルの容量不足
- LSTM のユニット数や CNN のフィルター数が少なすぎて、複雑なパターンを学習できていない。
- LSTM 層の数を増やす、Bidirectional を活用する、畳み込み層を追加する などの改善策が考えられる。
- ハイパーパラメータの最適化
- 学習率(Learning Rate)を調整(現在
0.0001→0.0005など試す) - バッチサイズの変更(現在
64→128にしてみる) - 正則化(Dropout, L2正則化)を調整(過学習を防ぎつつ、適度に表現力を持たせる)
- 学習率(Learning Rate)を調整(現在
- データ拡張(Data Augmentation)
- ノイズ追加、ピッチ変更、タイムストレッチなどの処理を適用済みか確認。
- 追加でデータ拡張を試す。
- エポック数が足りない
EarlyStoppingにより学習が途中で止まっていないか確認。- エポック数を
50→100に増やしてみる。
✅ 次にやること
- 05_04_model_evaluation_CNN_LSTM.ipynb を実行して、Confusion Matrix と精度指標を確認する
- 誤分類されやすいクラスを特定する。
- クラスごとの Recall, Precision を確認する。
- モデルの改善策を適用する
- 上記の改善策の中から、影響が大きそうなものを優先して試す。
- 例えば、
LSTM ユニット数を増やすor学習率を変更するなど。
📌 結論
まずは 05_04_model_evaluation_CNN_LSTM.ipynb を実行し、問題の詳細を把握しましょう!
その後、改善策を適用していく流れで進めます。