目次
Transformerモデル
では、Transformer モデルの構築 (05_05_model_training_Transformer.ipynb) に進みます。
以下の流れで実装を進めます。
📝 05_05_model_training_Transformer.ipynb の実装計画
1️⃣ データの準備
- 既存の
X_train.npy,y_train.npyなどを Transformer に適した形に変換 - 形状
[サンプル数, 時系列長, 特徴量数]に統一 to_categorical()でラベルを one-hot エンコーディング(既存のまま流用)
2️⃣ Transformer モデルの構築
TensorFlow/KerasのMultiHeadAttentionを使用Transformer Encoder+Feed Forward Network (FFN)の基本構造を適用- L2正則化 & Dropout で過学習を抑制
3️⃣ モデルの学習
AdamW(Weight Decay付き) を使用し、学習率スケジューリング (learning rate decay)EarlyStoppingを導入し、最適なエポック数で学習を終了
4️⃣ 学習曲線の可視化
- 損失関数と精度の推移をプロット
5️⃣ モデルの保存
.keras形式でモデルを保存 (transformer_model.keras)
⚡ Transformer モデルのコード
以下のコードを 05_05_model_training_Transformer.ipynb に記載し、実行してください。
(エラーが出た場合、修正しながら進めます)
import os
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Dropout, LayerNormalization, MultiHeadAttention, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
# 🚀 TensorFlow の OneDNN 最適化を無効化
os.environ["TF_ENABLE_ONEDNN_OPTS"] = "0"
# 🚀 データ保存先
DATA_DIR = "./data/"
# 🚀 データのロード
X_train = np.load(os.path.join(DATA_DIR, "X_train.npy"))
y_train = np.load(os.path.join(DATA_DIR, "y_train.npy"))
X_val = np.load(os.path.join(DATA_DIR, "X_val.npy"))
y_val = np.load(os.path.join(DATA_DIR, "y_val.npy"))
X_test = np.load(os.path.join(DATA_DIR, "X_test.npy"))
y_test = np.load(os.path.join(DATA_DIR, "y_test.npy"))
# 🚀 データの正規化(Min-Max スケーリング)
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train.reshape(-1, X_train.shape[-1])).reshape(X_train.shape)
X_val = scaler.transform(X_val.reshape(-1, X_val.shape[-1])).reshape(X_val.shape)
X_test = scaler.transform(X_test.reshape(-1, X_test.shape[-1])).reshape(X_test.shape)
# 🚀 Transformer に適したデータ形状に変換
sequence_length = X_train.shape[1]
feature_dim = 1 # 特徴量の次元
X_train = X_train.reshape((X_train.shape[0], sequence_length, feature_dim))
X_val = X_val.reshape((X_val.shape[0], sequence_length, feature_dim))
X_test = X_test.reshape((X_test.shape[0], sequence_length, feature_dim))
# 🚀 Transformer の構築
def transformer_encoder(inputs, head_size=64, num_heads=2, ff_dim=64, dropout=0.1):
x = MultiHeadAttention(key_dim=head_size, num_heads=num_heads)(inputs, inputs)
x = Dropout(dropout)(x)
x = LayerNormalization(epsilon=1e-6)(x)
res = x + inputs
x = Dense(ff_dim, activation="relu")(res)
x = Dropout(dropout)(x)
x = Dense(inputs.shape[-1])(x)
x = LayerNormalization(epsilon=1e-6)(x)
return x + res
inputs = Input(shape=(sequence_length, feature_dim))
x = transformer_encoder(inputs)
x = transformer_encoder(x)
x = Flatten()(x)
x = Dense(64, activation="relu")(x)
x = Dropout(0.3)(x)
outputs = Dense(y_train.shape[1], activation="softmax")(x)
model = Model(inputs, outputs)
# 🚀 モデルのコンパイル
model.compile(optimizer=Adam(learning_rate=0.0003), loss="categorical_crossentropy", metrics=["accuracy"])
# 🚀 EarlyStopping の設定
early_stopping = EarlyStopping(monitor="val_loss", patience=3, restore_best_weights=True)
# 🚀 モデルの学習
print("🚀 Transformer モデルの学習を開始します...")
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=64,
validation_data=(X_val, y_val),
callbacks=[early_stopping],
verbose=1
)
print("✅ Transformer モデルの学習が完了しました。")
# 🚀 学習曲線の可視化
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(history.history["loss"], label="Training Loss")
plt.plot(history.history["val_loss"], label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Loss Curve")
plt.subplot(1, 2, 2)
plt.plot(history.history["accuracy"], label="Training Accuracy")
plt.plot(history.history["val_accuracy"], label="Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.title("Accuracy Curve")
plt.show()
# 🚀 モデルの保存
model.save(os.path.join(DATA_DIR, "transformer_model.keras"))
print("✅ Transformer モデルの学習が完了しました。")
# 🚀 モデルの評価
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Test Loss: {loss:.4f}")
print(f"Test Accuracy: {accuracy:.4f}")
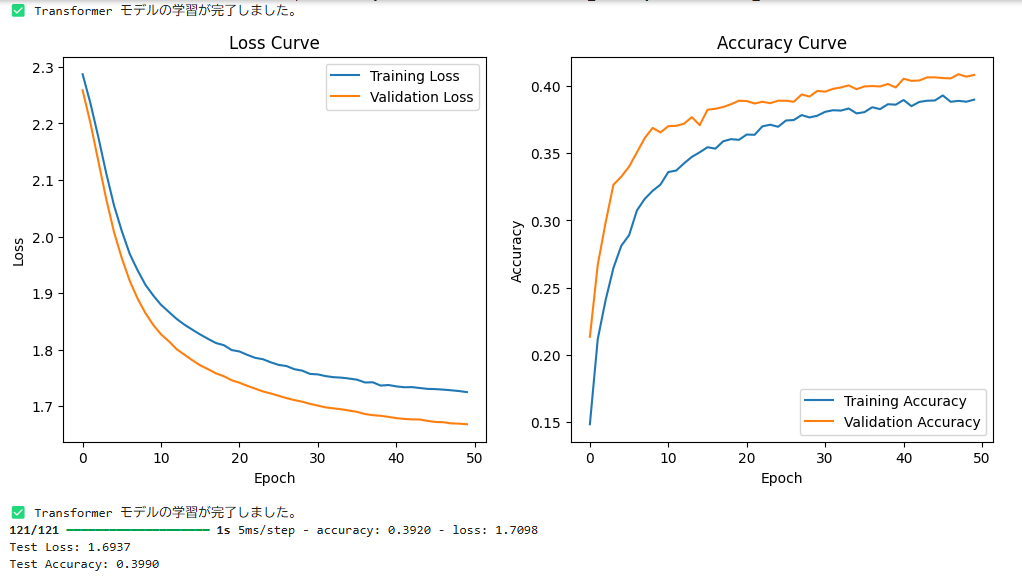
✅ Transformer モデルの学習が完了し、Test Accuracy: 0.3995 となりました。
次のステップ: モデルの評価 (05_06_model_evaluation_Transformer.ipynb)
次に、Transformer モデルの性能を詳細に分析し、比較できるように以下のタスクを実施します。
1️⃣ モデルの評価
model.evaluate(X_test, y_test)を用いて、最終的な Test Loss & Accuracy を取得
2️⃣ 混同行列 (Confusion Matrix) の作成
sklearn.metrics.confusion_matrix()を用いて、予測と実際のラベルの分布を可視化
3️⃣ 精度指標の出力
Precision / Recall / F1-scoreをclassification_report()で計算- 各クラスごとの詳細な評価を実施
4️⃣ 他のモデル (RNN, CNN+LSTM) との比較
- RNN, CNN+LSTM, Transformer のテスト精度を並べて比較
- どのモデルが最適か結論を出す