Transformerモデル(評価・調整)
import os
import numpy as np
import tensorflow as tf
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# データ保存先
DATA_DIR = "./data/"
# データのロード
X_test = np.load(os.path.join(DATA_DIR, "X_test.npy"))
y_test = np.load(os.path.join(DATA_DIR, "y_test.npy"))
# Transformer モデルのロード
model_path = os.path.join(DATA_DIR, "transformer_model.keras")
model = tf.keras.models.load_model(model_path)
# モデルの評価
loss, accuracy = model.evaluate(X_test, y_test, verbose=1)
# 結果を表示
print(f"Test Loss: {loss:.4f}")
print(f"Test Accuracy: {accuracy:.4f}")
from sklearn.metrics import confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
# 🚀 予測の実行
y_pred = model.predict(X_test)
y_pred_classes = np.argmax(y_pred, axis=1) # クラスラベルに変換
y_true = np.argmax(y_test, axis=1) # 正解ラベル
# 🚀 混同行列の計算
cm = confusion_matrix(y_true, y_pred_classes)
# 🚀 混同行列のプロット
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues', xticklabels=range(10), yticklabels=range(10))
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.title("Confusion Matrix")
plt.show()
from sklearn.metrics import classification_report
# 🚀 クラス別の精度指標(Precision / Recall / F1-score)を算出
report = classification_report(y_true, y_pred_classes, digits=4)
# 🚀 結果の表示
print("Classification Report:\n")
print(report)
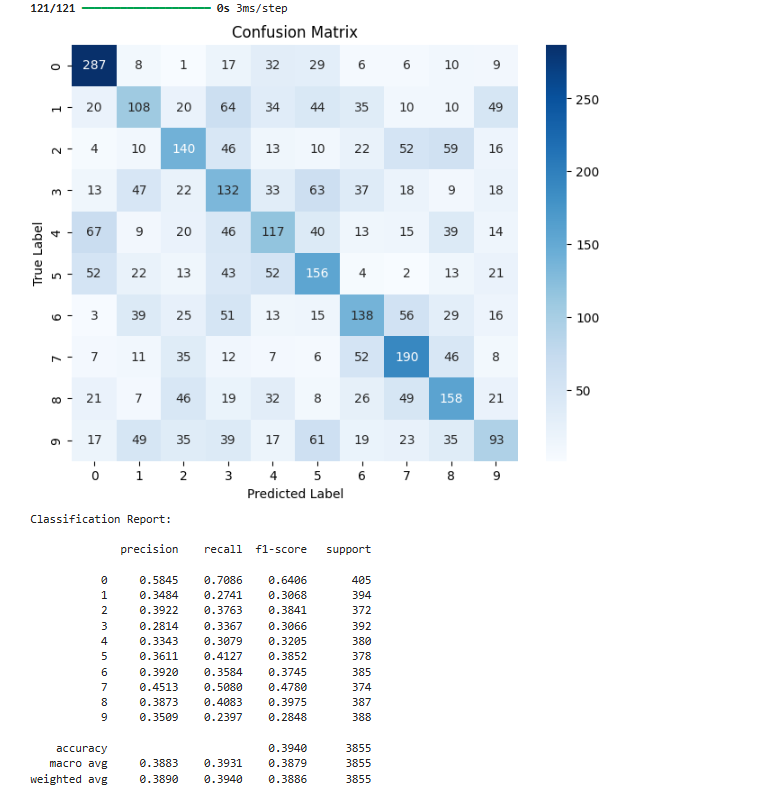
他のモデル(RNN, CNN+LSTM)との比較
分類レポート(Classification Report)が出ましたね。次は、他のモデル(RNN, CNN+LSTM)と比較し、最も適したモデルを選定します。
比較するポイント
- 全体の精度(accuracy)
- Transformer: 39.40%
- CNN+LSTM: 39.90%
- 各クラスの F1-score の比較
- どのモデルが各クラスに対して高い精度を持つか?
- Transformer はどのクラスで特に強いか、弱いか?
- 学習時間と収束性
- 収束が速いモデルはどれか?
- 学習に時間がかかりすぎていないか?
タスク
- CNN+LSTM, RNN の Classification Report を出力
- 過去の RNN, CNN+LSTM の classification_report をアップロードしてください
- それらと Transformer の精度を比較
- 結果の考察
- どのモデルが最も適しているか?
- 改善の余地があるか?
- 今後の方向性を決定